
.jpg)
One of our clients is a US law firm that helps people with disabilities apply for government benefits. To file a single claim, a lawyer had to read through hundreds of pages of medical records and cross-check them against the rules of a specific state. Each case took about a week. We built an NLP agent for them. Now the processing takes 5 minutes and runs at 90% accuracy. The full case study is on our website.
Businesses run into this kind of problem all the time. Contracts, medical records, support tickets, customer email threads, all of it is just text that somebody has to read. Natural language processing lets you seriously streamline that whole process.
Below we break down what NLP actually looks like today. How natural language understanding differs from natural language generation. What a modern NLP stack is made of. And where it actually pays off. This is the same stack we use every day when we build custom NLP solutions for clients.
What Is NLP in AI?
Natural language processing is a branch of artificial intelligence that deals with how computers handle human language in written or spoken form. That's the short NLP definition. The term itself goes back to the 1950s, when Alan Turing, in his paper on machine intelligence, proposed the criterion later known as the Turing test. But what we actually mean today by NLP in AI is a stack that took shape over the last seven or eight years, and it rests on two things. Large volumes of data, and the transformer architecture.
How NLP Brings Linguistics, Machine Learning, and AI Together
To see why NLP is a discipline in its own right rather than just ML applied to text, it helps to look at where it came from. It started with classical linguistics, which describes language through rules. Up until the 2010s, an engineer would manually specify that "New York" refers to a city rather than a verb, and thousands of rules like that would pile up.
Machine learning offered a different path and flipped the whole approach on its head. Instead of rules, examples, from which the model figures out the patterns on its own. The first serious breakthrough in NLP machine learning came in 2013, when Google released Word2Vec, a model trained on statistics of how often words appear together in text. It picked up on its own that "king" and "queen" are related in the same way as "man" and "woman". That was the moment language first became a mathematical object you could do arithmetic with.
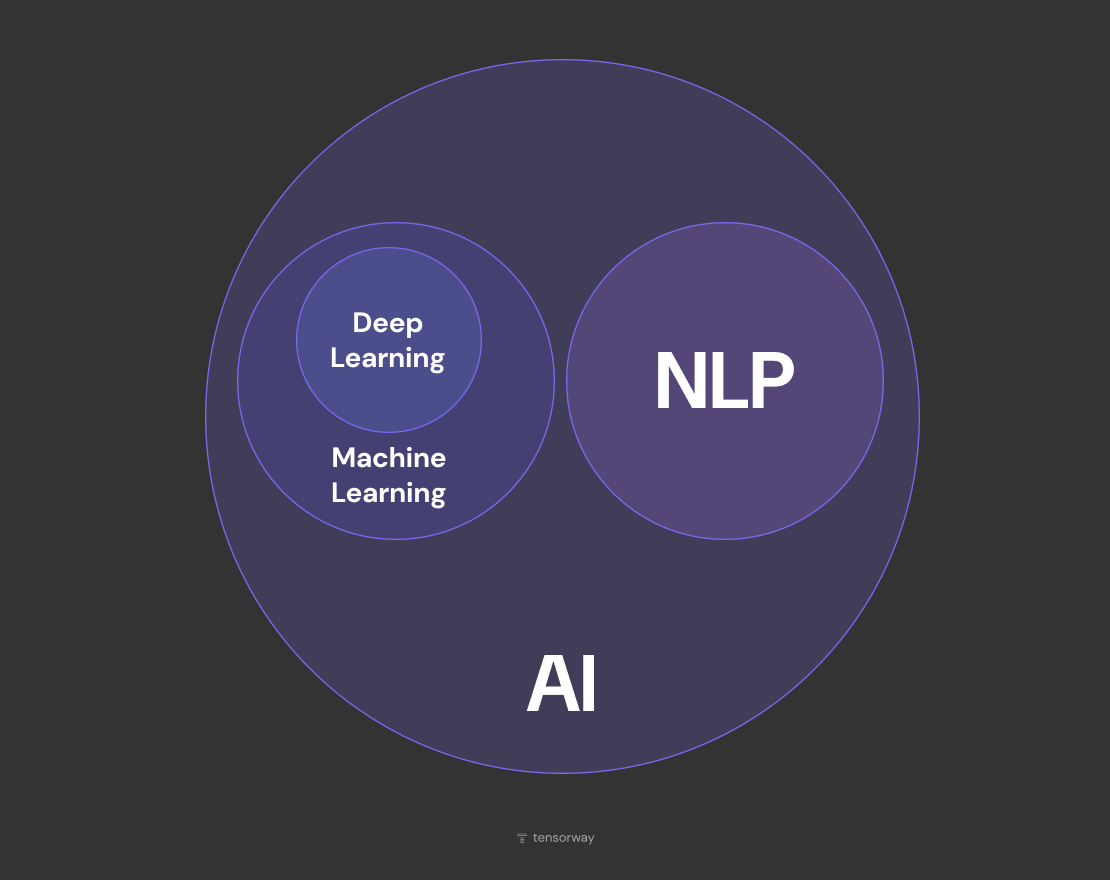
In this hierarchy, NLP sits at the intersection of three layers. As part of AI broadly. As a consumer of ML and deep learning methods specifically. And as a field of its own, because its material is language, and you can't work with language the same way you work with numerical data or images.
What Happened in 2017
In June 2017, the Google Brain team published a paper called "Attention Is All You Need", which introduced the transformer architecture and effectively closed the era of recurrent models. Before that, text was processed sequentially, one word at a time, which limited both training speed and the model's ability to hold on to long context. The transformer removed that limit with a self-attention mechanism, which lets the model "see" all words in a sentence in parallel and weigh which ones matter for interpreting which others.
The fallout from this breakthrough shaped the entire decade in NLP that followed. The very next year Google released BERT, OpenAI shipped the first GPT, and after that things moved fast. GPT-3 in 2020, ChatGPT in 2022, GPT-4, Claude, Gemini, all of them built on the same basic architecture from that one paper.
Core NLP Tasks
When companies turn to NLP development services like ours, the pipeline usually starts the same way. An NLP system takes in text directly, audio by way of speech recognition, or video, from which the audio track or subtitles are pulled out. After that the actual tasks begin. Among the main natural language processing techniques you'll see in production, five show up most often.
- Raw language processing, meaning cleaning the text, tokenization, lemmatization. A technical stage that often gets underestimated, even though this is where most systems actually break.
- Entity extraction, which pulls names, dates, amounts, addresses, and numbers out of text.
- Relationship extraction, which figures out how entities are connected to each other. The model doesn't just register that several people are mentioned in the text. It also works out that one of them signed the document and another one notarized it.
- Topic classification, which sorts text into a category.
- Sentiment analysis, which figures out the emotional tone.
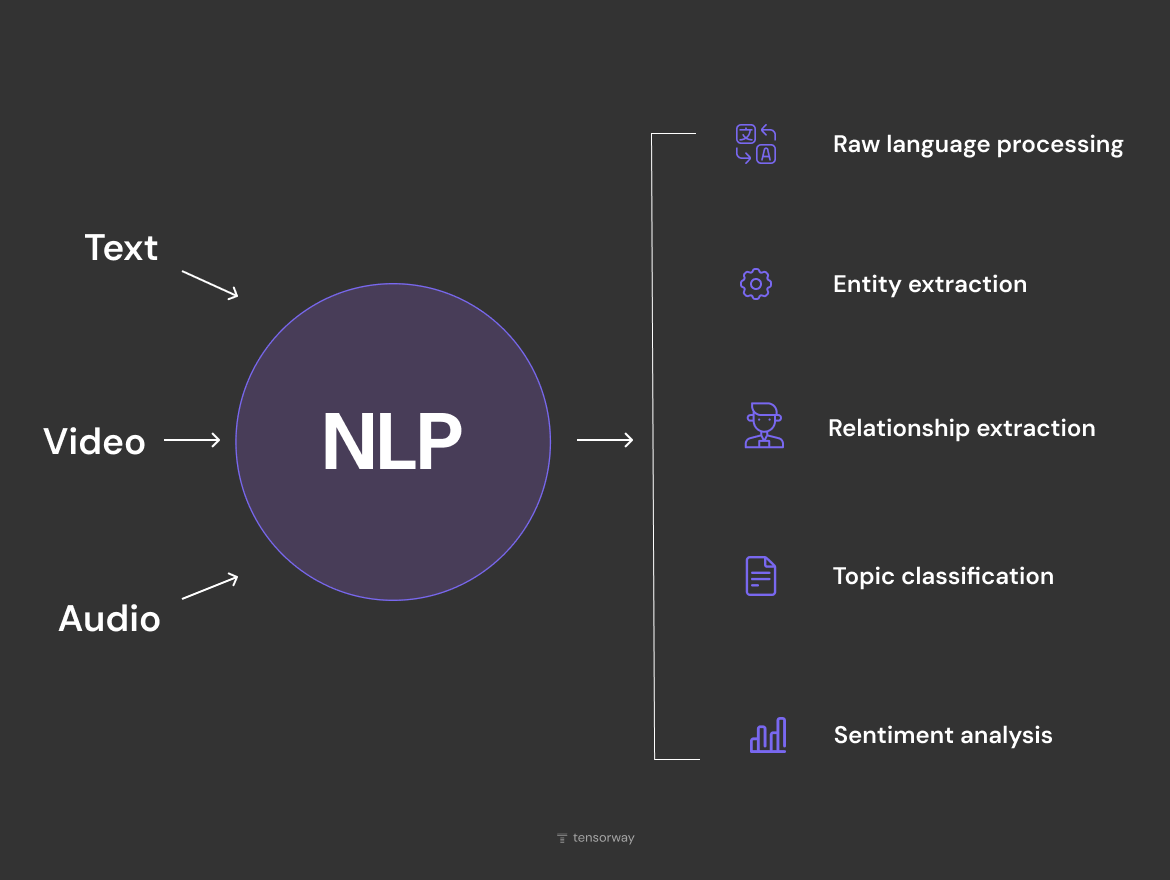
Each of these five sits on top of the same NLP machine learning foundation: embeddings, a transformer backbone, and a task-specific layer.
Breaking Down NLU and NLG
When people talk about NLP meaning in a broad sense, what they usually have in mind is one of two halves. The first half is about understanding what the person just said. The second is about what the machine is going to say back. It's worth keeping these apart, because the two halves get solved with different architectures, they get graded against different metrics, and in a lot of companies they end up owned by entirely different teams.
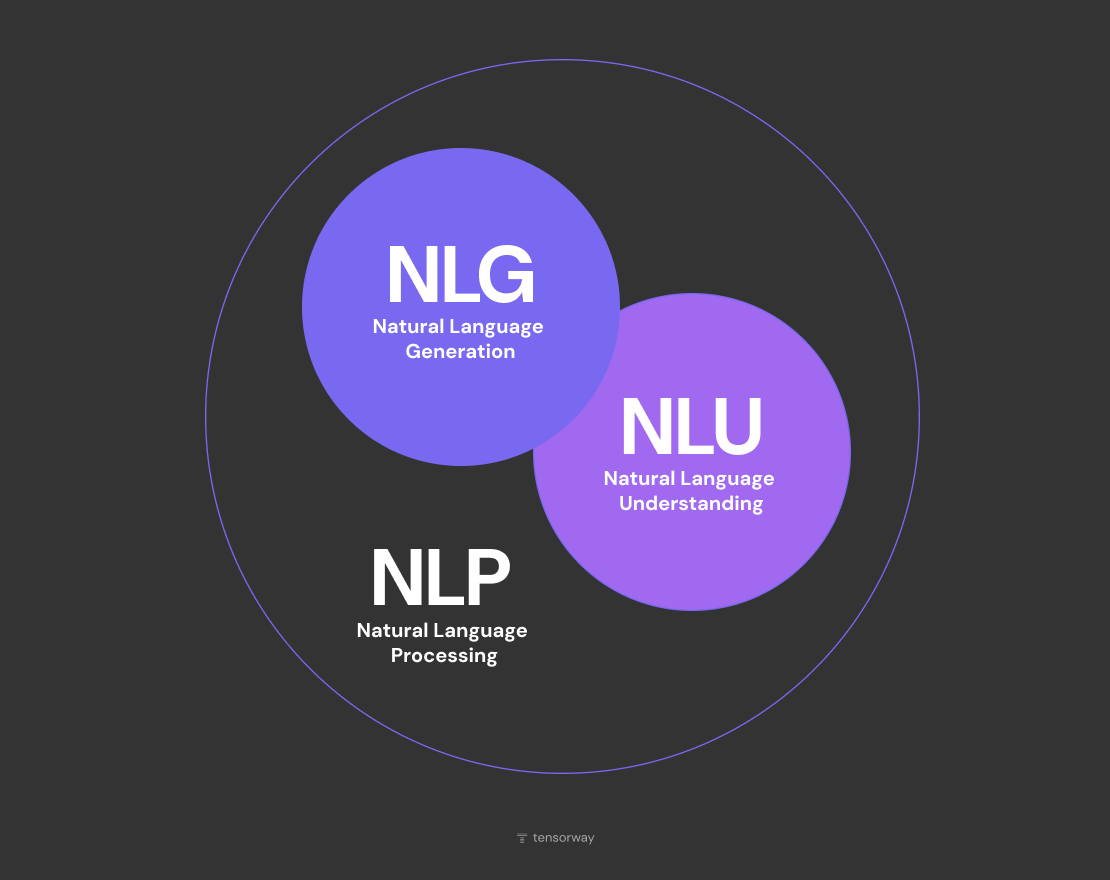
What Is Natural Language Understanding (NLU)?
NLU is in charge of the input side of an NLP system. Its job is to take an unstructured message from a human and turn it into structured data that the business logic can actually act on.
In practice, NLU is answering two basic questions. What is this text about, and what exactly does it say. The output always comes out as some kind of structure that the rest of the system can then use to make a decision.
Technically speaking, the whole thing happens in four steps.
- First the text gets chopped up into tokens, which are either whole words or pieces of words. Each of those tokens then gets mapped to a numeric vector sitting in a high-dimensional space, where words with similar meaning end up near each other. Those are embeddings.
- After that, a neural network, almost always a transformer these days, runs over the whole sequence of vectors and uses self-attention to figure out how much weight each token should carry given everything else around it. And finally, there's a task-specific layer on top that produces whatever the actual output is supposed to look like. If the task is classification, you get class probabilities. If it's NER, you get a tag hanging off each token. If it's sentiment analysis, you get a score on some scale.
What Is Natural Language Generation (NLG)?
NLG is doing the opposite job. The input is either structured data or some other text, and the output is natural-sounding language that a human can actually read.
Under the hood, NLG is what's called an auto-regressive process. The model doesn't spit out the whole answer in one shot. It produces it one token at a time. Each new token gets picked based on everything that's been generated up to that point, plus the original prompt on top of that. What's going on internally is that the model is computing a probability for every possible next token in its vocabulary, and then picking one according to some strategy.
That strategy is called sampling, and it's what really controls the character of the output. The temperature parameter sets how much variety you get. Crank it low, and the model will just pick the most likely option every time, which gives you predictable text that tends to repeat itself. Crank it high, and less likely tokens start getting picked, the text gets more varied, but you also start running into weirdness. Top-p and top-k are different flavors of filtering. They both narrow the pool of candidate tokens down to just the most probable ones.
How NLU and NLG Work Together
In most production systems, both halves run back to back. The user types or says something, NLU takes the message apart, the business logic decides what to do, and then NLG puts together a response. That closes the loop.
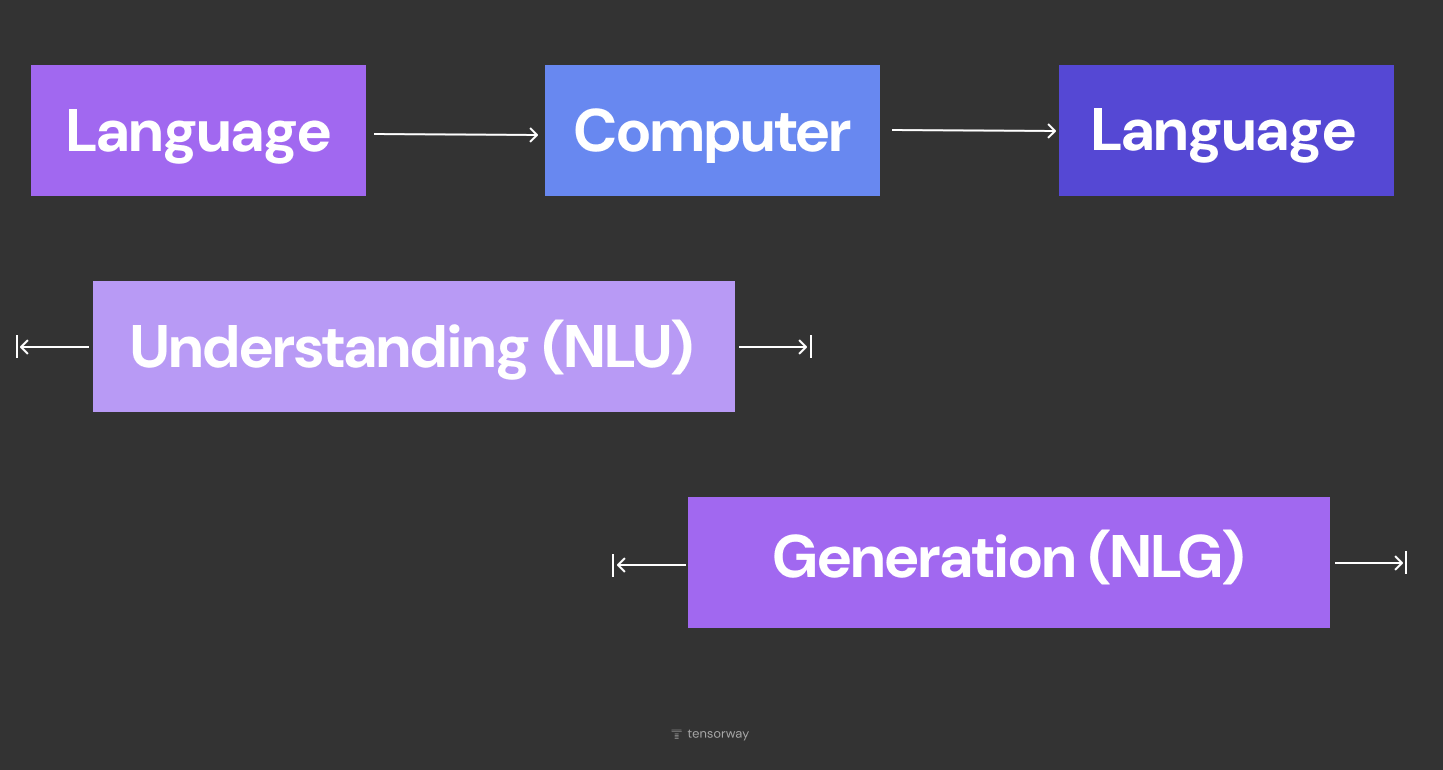
The reason the natural language understanding vs natural language generation distinction matters isn't just academic. They fail in pretty different ways. NLU can get the intent wrong, and if it does, the whole chain downstream goes off in the wrong direction. NLG can spit out something that sounds totally convincing but contains a factual mistake. That's model hallucination, and it's a separate class of risk that needs its own guardrails in place.
Real-World NLP Use Cases Across Industries
Over six years working in production AI, we've shipped natural language processing solutions for clients in law, finance, education, and fintech. Every industry shows up with its own quirks, but the underlying economics of rolling this stuff out look roughly the same everywhere. NLP earns its keep in the places where a big backlog of unstructured text has piled up, and where going through it by hand has gotten either too slow or too expensive. The applications of NLP below are four cases where that plays out most clearly, and they double as practical natural language processing examples from our own work.
Customer Support Automation
Support teams were the first serious beachhead for NLP inside a business. Once you're looking at thousands of those a day, even a second spent per ticket starts multiplying into real hours pretty fast.
Modern setups run NLP at a few different layers at once. One model takes the request and routes it to whichever queue it belongs in. Entity extraction grabs the order number and the customer's email and drops them straight into the CRM. A generative model takes a first pass at drafting the reply, pulling from the internal knowledge base as it goes. The agent isn't writing from a blank page anymore. They're reading, sanity-checking, and hitting send.
The business case isn't really about swapping people out for bots. It's that a single agent can close more tickets in the same shift. In a big support org, that ends up reshaping the headcount plan, and it does it without the service quality dropping off.
Legal Tech and Document Processing
In documents with multi-page structure, the model has to understand more than just the text. It has to know where in the layout something is sitting. A number inside an "invoice number" row and a number inside a "PO reference" field are not the same thing, even though on paper they look identical. That's the exact reason plain OCR falls short here, and why you need an NLP layer sitting on top of it.
That US law firm we mentioned up front is a good example of how this plays out. The lawyer was burning a full week matching hundreds of pages of medical PDFs against a given state's rules. The NLP agent wraps up the same job in 5 minutes, and it comes in at 90% accuracy. Full case study is up on the site.
The second story is more on the fintech side. Flexidea is a platform that automates invoice fill-in from scans their users upload. Off-the-shelf OCR was converting images to text fine, but it kept getting confused about which field was which. We put a custom NLP layer over the OCR, built on a NER model we trained specifically for this. It reads the document structure and handles Latvian, a language there were basically no ready-made solutions for on the market.
When the document volume gets big enough, every percentage point of model accuracy and every minute shaved off per document ends up showing up on the P&L.
Finance
In finance, NLP mostly gets applied along two broad tracks. The first is compliance and fraud detection, where models are reading through transaction memos, internal correspondence, and company documents looking for stuff that doesn't fit the usual pattern. The second one tends to fly under the radar more, and that's investment research and deal sourcing.
One of our clients, a Stockholm-based private equity fund, invests across healthcare, tech, and industrial services. Their analysts were putting in roughly 60 hours a week just on market research and valuation work. A single deal could take anywhere from a couple of days to a month to process. Working out the BVI for a typical target was eating up 20 to 50 hours by itself.
We built out a multi-agent AI system for their entire sourcing pipeline. Under the hood, it's an LLM Core running on Azure OpenAI, Gemini, Anthropic, and Deepseek, with a chat interface on top where the analyst asks whatever they need to know in plain language and gets an answer back, stitched together from actual documents and databases. Initial screening got 80% faster. Prep time for the investment committee dropped by a factor of eight. The analysts got to go back to doing strategy work instead of manually scraping data together.
Education and EdTech
In education, NLP lands differently. The student isn't paying for automation, they're paying for the quality of the feedback they get. That's why, in our AI chatbot development services, an AI system here has to hit the level of an actual teacher, and if it doesn't, there's really no point in it being there at all.
Our client runs GAMSAT prep, which is the entrance exam for medical schools in Australia. He needed to scale without the quality slipping. The official ACER system was only giving ballpark scores. A competitor, Frasers, had already rolled out their own AI product. So what he needed was something that went past just grammar checking, something that could write stylistic feedback in the voice of this particular tutor.
On the technical side, it's a fine-tuned LLM with retrieval-augmented generation layered in. The model was further trained on the client's own books, courses, and video lectures. Orchestration sits on LangGraph and LangChain, with the base models coming from OpenAI. The finished system writes feedback in the voice of a specific expert, and it lets the tutor take on a lot more students without the essay review quality taking a hit.
How to Get Started with NLP
The first question we usually hear from a new client is whether they should grab an off-the-shelf model or train their own. There's no clean answer, but there's a rule of thumb that tends to hold up. If the task boils down to pulling a set of typical fields out of typical documents, a ready-made API from OpenAI, Anthropic, or Azure will cover it within 2 to 4 weeks. On the other hand, if accuracy is going to feed into regulated decisions, or the data legally can't leave the company perimeter, or the domain is so narrow that a general-purpose model trips over the vocabulary, then you're going to need your own pipeline.
ROI on NLP doesn't get counted in hours saved. It gets counted on the delta between how the workflow runs today and how it runs after. Meaning, what does it cost right now to process a single document, versus what does that same job cost in the automated pipeline with a human verifier sitting at the end of it. Take that difference, multiply by volume, and that's the economic impact.
Conclusion
NLP in 2026 isn't exotic anymore. The tooling is mature, and you can have something running in production within a couple of weeks. The real question isn't whether it works, it's where to point it. If your team is stuck reading through stacks of contracts, records, tickets, or filings that nobody really has the bandwidth for, there's almost certainly a case for NLP on your side. The part worth talking through before anyone writes code is where to start so the first result lands in weeks rather than quarters. Get in touch with us, and we'll map it out together.

%20(1).jpg)
.jpg)


