%20(1).jpg)
Investment in ML grows every year, but the number of projects that actually make it to production grows disproportionately slowly. According to a RAND Corporation study from 2024, over 80% of AI projects never reach production. That is twice the failure rate of IT projects without an ML component. An S&P Global survey from 2025 confirms this trend. 42% of companies shut down most of their AI initiatives entirely, compared to just 17% the year before.
In most cases the reason for failure lies outside the model itself. A poorly defined business objective, inconsistent data, no established process for moving a model into production. Each of these problems occurs at a specific stage of the machine learning lifecycle, and it is the disciplined execution of every stage that determines whether a model becomes a working product.
In this article we break down the full machine learning development life cycle. Every phase, from problem definition to model monitoring in production, with a focus on where the biggest risks emerge and how to minimize them.
What Is the Machine Learning Model Lifecycle?
Every ML project goes through a set of repeating stages. From defining the business problem to monitoring the model in production. This sequence is the machine learning development services.
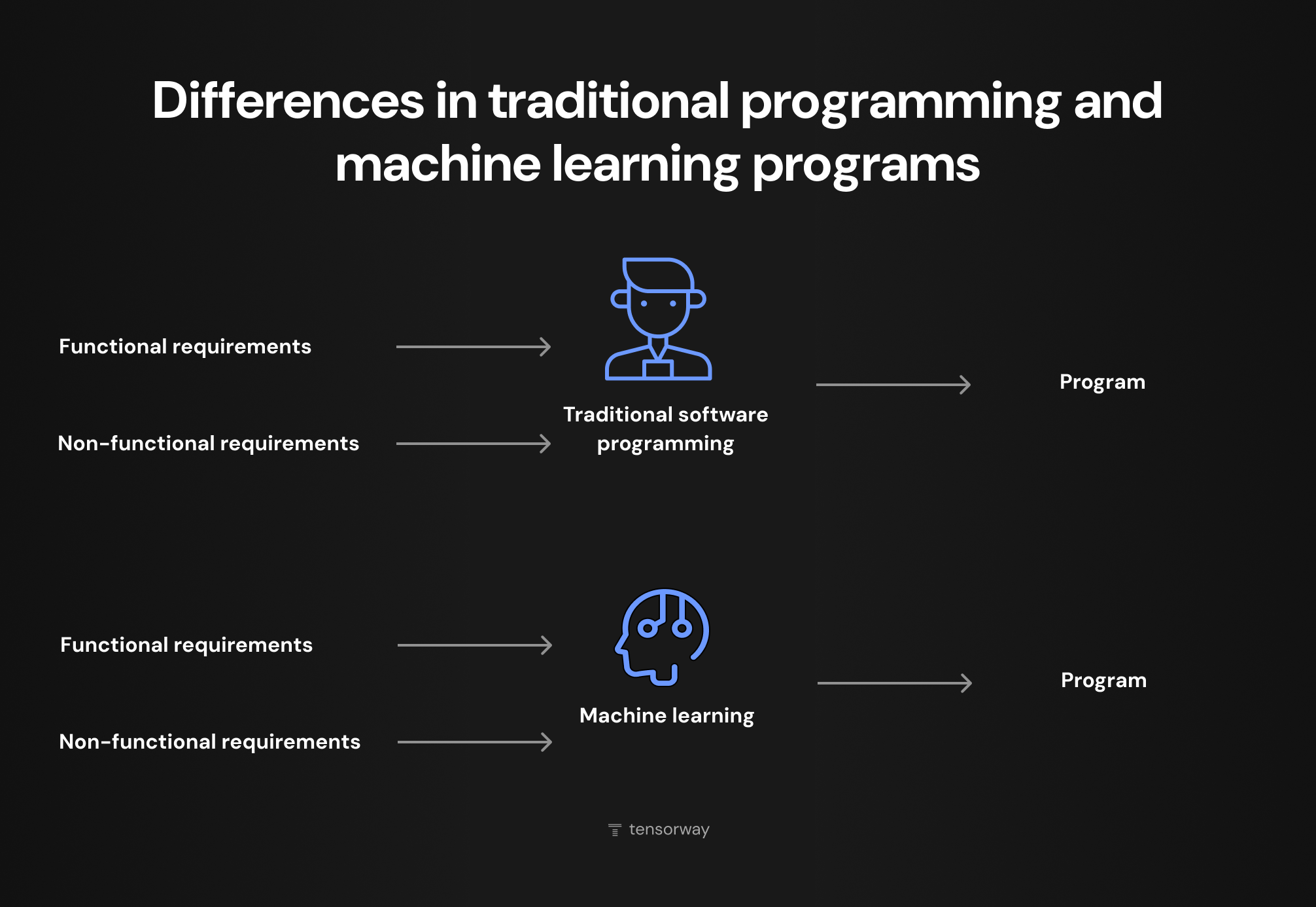
At first glance the ML development life cycle resembles the classic SDLC that most engineering teams already know well. Both processes include planning, development, testing and maintenance. But that is where the similarity ends. ML projects introduce stages that simply do not exist in traditional software development. Data collection and preparation, model training, validation on unseen data, tracking drift after deployment. Each of these stages can send the team several steps back. If a model shows poor accuracy during validation, the team needs to revisit the data or rethink the approach to feature engineering.
This iterative nature is what makes the machine learning model development life cycle more complex than a linear pipeline. Teams that treat the ML process as a strict sequence without built-in feedback loops will almost certainly run into problems at deployment or immediately after it.
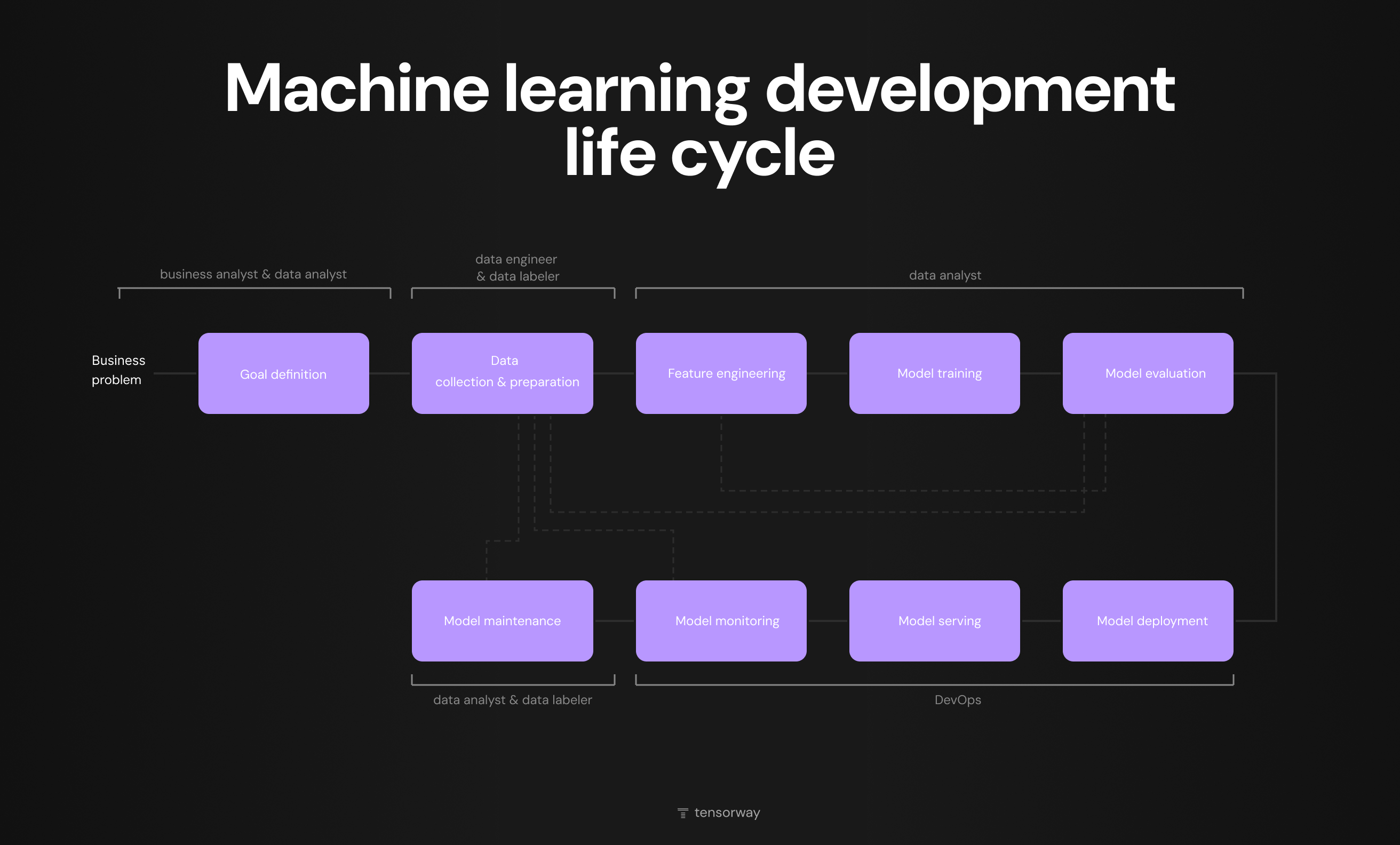
Key Stages of the Machine Learning Lifecycle
The diagram below shows the full ML lifecycle with all stages and the roles involved at each one. The process starts with a business problem and goes through nine stages from goal definition to model maintenance. Dotted arrows indicate that at any stage the team can loop back to data collection or feature engineering if results do not meet expectations.
It is worth paying attention to how responsibility is distributed. The early stages involve business analysts and data analysts, the middle part of the lifecycle is the domain of data engineers and data scientists, and deployment, serving and monitoring shift to DevOps. It is exactly at the boundaries between these zones where communication gaps most often appear, slowing down or stalling the ML project entirely.
Below we walk through each stage individually.
Stage 1. Goal Definition
Every ML initiative starts with a business problem that needs to be clearly translated into a machine learning task. At this stage stakeholders and the technical team align on several key questions.
- What specific business metric we want to improve.
- Whether this is a classification, regression, clustering or recommendation task.
- What data is already available and how well it fits the problem.
- What minimum model quality threshold will be acceptable for the business.
A general objective like reducing customer churn needs to become a concrete task. For example, predicting the probability of churn for each user within a 30-day window with a target precision above a defined threshold.
Without this level of specificity the team risks spending months building a technically sound model that solves the wrong problem. If the team lacks experience in translating business objectives into ML tasks, this is the stage where AI consulting services add the most value. Defining evaluation criteria and business KPIs at this stage saves significant time and budget at later stages of the ML model lifecycle.
Stage 2. Data Collection and Preparation
Once the problem is defined, the team moves on to collecting and preparing data. This is the stage where data engineers and data laborers play a key role.
Sources may include internal databases, CRM systems, event logs, external APIs or public datasets. In practice it is rare for a single source to fully cover the needs of a model, so teams typically combine several. A separate situation arises when real data is insufficient or contains sensitive information that cannot be used directly. In such cases teams increasingly turn to synthetic data, which replicates the statistical properties of real datasets without the risk of privacy violations.
But collecting data is only half the work. Raw data almost always contains missing values, duplicates, outdated records and format inconsistencies across different sources. If these problems are not resolved at this stage, they will surface as poor model quality and the team will end up back here anyway. This is why data preparation consistently remains one of the most time-consuming stages of any ML lifecycle.
Stage 3. Feature Engineering
Prepared data is not yet ready for model training. It needs to be transformed into features that the model can interpret. From a transaction date you can extract the day of the week or the number of days since the last purchase. Numerical fields need to be normalized, categorical variables encoded, outliers handled or removed.
At this stage it is critical to involve people who understand the subject domain. Automated feature selection works, but there are signals that can only be identified through knowledge of business logic. Often a single well-constructed feature improves the result more than switching to a more complex algorithm.
If during feature engineering it becomes clear that the available data is not enough, the team goes back to Stage 2. On the ML lifecycle diagram this iteration is shown with dotted arrows.
Stage 4. Model Training
Once features are ready, the team selects an algorithm and begins training. The choice depends on the task, the volume of data and how much resource is available for development and ongoing model support in production.
Training typically starts with a simple model. It becomes the baseline against which more complex approaches are later compared. Moving to a heavier architecture only makes sense if the metric improvement justifies the additional infrastructure cost, development time and maintenance effort. In practice gradient boosting on tabular data often handles the task no worse than a neural network that costs significantly more to support.
Stage 5. Model Evaluation
A trained model needs to be evaluated before moving to deployment. At this stage the team checks how well the model results align with the business criteria that were defined back at Stage 1.
Technical accuracy on its own says very little. What matters far more is how that accuracy translates into a business outcome. Whether the model reduces the number of incorrect decisions compared to the current process. Whether it shortens processing time. Whether it justifies the cost of its own support in production. These are the questions that determine if the model is ready to move forward.
If the results do not meet expectations, the team goes back to feature engineering, to the data or to algorithm selection. This is a normal part of the process, and it is where the iterative nature of the ML lifecycle shows itself most clearly.
Stage 6. Model Deployment
The model has passed evaluation and is ready for production. At this point responsibility shifts from data scientists to the DevOps team. And it is exactly at this handoff where time, context and quality are often lost.
A model that worked in an isolated development environment needs to become part of real infrastructure. This means containerization, setting up a CI/CD pipeline, integration with existing services and ensuring stable performance under load. Deployment options depend on the task. REST API for real-time predictions, batch inference for processing large volumes of data on a schedule, edge deployment if the model needs to run on a device without a constant server connection.
One of the biggest mistakes at this stage is pushing the model to production across all traffic at once. A safer approach is canary release or shadow mode, where the model runs in parallel with the current solution and its results are compared without affecting end users.
We covered production rollout strategies in detail in a separate article on ML model deployment.
Stage 7. Model Serving
On the diagram model serving stands separately from deployment, and this is not accidental. Deployment is the process of moving a model to production. Serving is how the model handles requests after deployment on an ongoing basis.
At this stage the team needs to ensure stable model performance under real load. Latency, throughput and fault tolerance all become the responsibility of the infrastructure team. If the model responds in 500 milliseconds instead of the expected 50, for the business it may be effectively unusable even with high accuracy.
Versioning also needs to be thought through. Several model versions can run in production simultaneously, for example for A/B testing or a gradual transition to a new version. Without a clear versioning system, rolling back to a previous model when problems arise turns into a chaotic process with unpredictable outcomes.
Choosing the right approach for a specific business problem is where team experience matters, or an external ML partner who has already worked on similar cases.
Stage 8. Model Monitoring and Maintenance
Deploying a model to production is not the final stage. It is the beginning of a new cycle. An ML model, unlike traditional software, degrades over time even if nothing in the code has changed. User behavior evolves, market conditions shift, and the data the model was trained on gradually stops reflecting reality.
The scale of this problem is confirmed by a study published in Nature Scientific Reports, conducted by teams from MIT, Harvard and Cambridge. Across 128 model-dataset pairs from four industries they observed quality degradation in 91% of cases. Different models on the same data degraded at different rates, making it nearly impossible to predict when failure will occur without monitoring.
This is why after deployment the team needs to track prediction quality on real data, detect data drift and concept drift, and have a clear retraining strategy. The approach can be scheduled, where the model is retrained at regular intervals, or triggered, where retraining is launched automatically when metrics fall below a defined threshold. Feedback from production brings the team back to the beginning of the ML lifecycle, and it is this loop that makes the ML life cycle truly cyclical.
ML Lifecycle in Practice: AI-Powered Legal Automation
Every stage we described above may look straightforward in theory. But on a real project they overlap, repeat and often come in a different order than expected. Below we show how this works on the example of one of our projects.
Goal Definition
A US-based law firm handling hundreds of disability cases at a time came to us with a specific problem. Their attorneys were spending up to a week manually reviewing the medical history of a single client. The goal was to cut that time without losing the quality of analysis.
Data Collection and Preparation
A single PDF could contain anywhere from a few hundred to ten thousand pages: scanned prescriptions, handwritten doctor's notes, lab results, imaging and administrative paperwork. All in one file with no structure. The system had to first determine which pages were relevant to the case and only then split the file into logical blocks.
Feature Engineering and Model Training
The content varied widely, so we used a combination of text-based language models for structured text and vision models for handwritten notes and scans. Every item in the final report links to the specific page in the original document so the attorney can verify the source instantly.
Model Evaluation
The first module cut processing time from a week to 5-15 minutes. But evaluation was not just about speed. For a legal business it is critical that the system does not miss significant medical information. So validation was done together with the client's attorneys on real cases.
Deployment, Serving and Maintenance
The project handles highly sensitive medical and legal data, so deployment required isolated AI infrastructure, access control and encryption. One of the integration challenges was that the SSA government portal has no public API, so we built a custom scraper that interacts with the portal by emulating real user actions.
Iteration
The result of the first module changed the nature of the collaboration. The client started bringing new problems, each building on the data infrastructure we had already put in place. Automated case monitoring through the government portal. CRM reconciliation that replaced 4 days of manual audits every month. A referral scanner that classifies cases by category and turned previously rejected clients into a new revenue stream. The project has been running for over 1.5 years and continues to grow.
Conclusion
The machine learning lifecycle is an engineering process that determines whether a model reaches production and stays there. Teams that skip stages or treat the process as linear run into the same problems highlighted by the RAND and S&P Global research.
Every stage from problem definition to monitoring exists because ignoring any one of them costs more than doing it. If your team is planning an ML initiative or has already hit roadblocks on the way to production, we are ready to discuss your case and help identify where exactly the process needs attention.



.jpg)

