

TL;DR
- Synthetic data generation with diffusion models helps when real datasets are too small, too expensive, or too locked down by privacy rules to train a reliable model.
- Diffusion models are more stable than GANs and produce more varied data, because their denoising process avoids the mode collapse that makes GANs repeat the same output. They are slower to generate, which is the main tradeoff.
- They work best for rare or high-risk edge cases like crash scenarios and brain anomalies, privacy-restricted tabular data in finance and healthcare through TabDDPM, auto-labeled computer vision datasets, and rebalancing underrepresented classes.
- Training one from scratch is rarely worth it. Most teams fine-tune a pre-trained model on their own data, then check quality with FID for images or Train-on-Synthetic, Test-on-Real for tables.
- If the seed data carries hidden bias, the model amplifies it. Garbage in, garbage out applies here too.
One of the biggest bottlenecks in modern machine learning production is the scarcity of training data. Quite often, real-world datasets are restricted by privacy compliance or are too expensive to collect and label manually. As a result, they can be too small to train deep neural networks. When your underlying data is unbalanced or lacks critical edge cases, the resulting machine learning model fails to perform reliably under live user traffic.
Nevertheless, synthetic data generation helps engineering teams bypass this data bottleneck. Diffusion models significantly change how artificial examples for training are created. They utilize a unique denoising mechanism that avoids historical training instabilities and mode collapse. Thanks to this, they ensure significantly higher structural fidelity and statistical diversity than previous generative frameworks.
In this article, we will take a closer look at the use of diffusion models for synthetic data generation. We will explore the underlying mechanics and identify the strongest use cases for this approach.
What Are Diffusion Models?
Diffusion models are a specialized class of generative AI synthetic data architectures. They learn to create realistic data by reversing a gradual noise-injection process. They do not rely on adversarial training like older frameworks. As a result, generated synthetic data preserves the full diversity and intricate details of your original dataset.
Diffusion models are trained to destroy information and then reconstruct it. This ensures high fidelity of synthetic data. The model of this type can take a completely blank canvas of digital static and transform it into an incredibly accurate synthetic sample.
How Do Diffusion Models Generate Synthetic Data?
When you work with diffusion models, the synthetic data generation mechanism relies on two distinct phases: the forward process and the reverse process.
- Forward process. The AI takes your real data and adds tiny layers of Gaussian noise over multiple steps. The system repeats this process until your original file is completely gone, while only pure noise remains. This step is vital because it forces the AI to study the exact statistical structure of your data before erasing it.
- Reverse process. This is where the actual generation happens. The network learns to undo the damage by removing the static, one layer at a time. To create fresh synthetic data, you simply feed the network a blank sheet of random noise. The AI cleans it up step by step until a sharp, realistic sample appears.
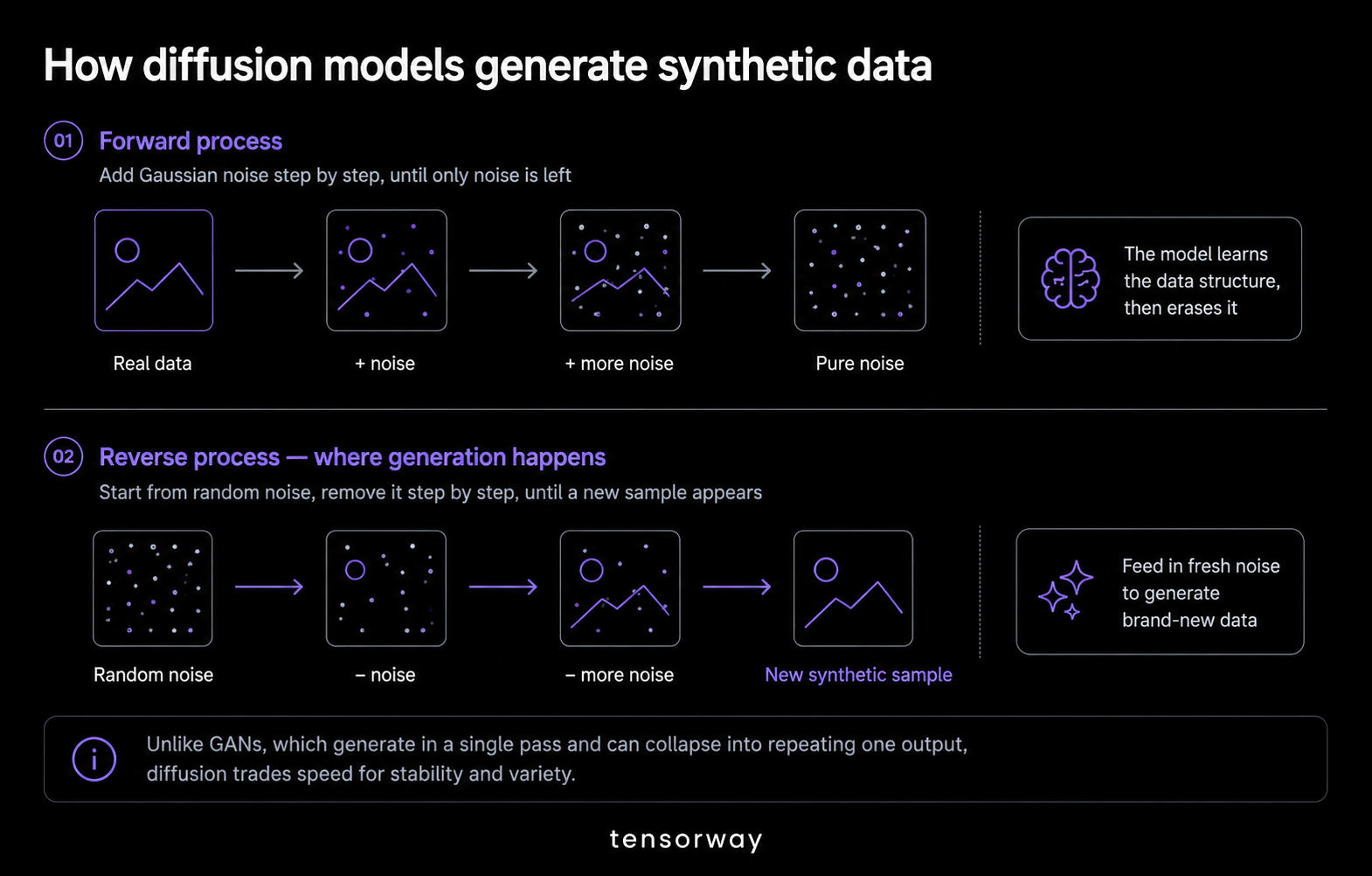
Historically, engineering teams relied on Generative Adversarial Networks (GANs) for data generation. However, GANs are unstable. They work by forcing two different AI networks to compete directly against each other. If one network wins too easily, the whole system breaks down. The AI gets trapped in a loop and generates the exact same output over and over again. This situation is known as mode collapse.
Diffusion models sample across the entire data distribution. This allows them to produce far more diverse and statistically accurate synthetic datasets. Denoising Diffusion Probabilistic Models (DDPM) and Stable Diffusion-based architectures are the most common options for image synthesis. Meanwhile, TabDDPM has become the leading approach for generating realistic tabular data.
Diffusion models deliver superior data quality. However, they come with inference speed, which is a serious engineering tradeoff. A diffusion model must iteratively clean data over dozens of steps. This leads to longer times needed to generate a single sample in comparison to a GAN, which can produce an output in a single forward pass.
Due to this, training a diffusion model completely from scratch is rarely practical for a growing tech team. The most efficient route to production is to fine-tune a pre-trained model on your specific domain data.
The table below contains the key differences between GAN vs diffusion model for synthetic data generation.
What Are the Best Use Cases for Synthetic Data Generation with Diffusion Models?
In many specific domains, engineering teams struggle to collect training data on rare or high-risk events (for example, in the automotive industry, these can be complex car crashes). Collection of this type of data can be dangerous and unethical. Diffusion models solve this issue. They simulate highly diverse, realistic accident scenarios to train self-driving systems safely in virtual environments. As researcher Jun Zhu highlighted in the article published by the National Science Review, synthetic data generation can be more cost-effective, time-efficient, and privacy-preserving than collecting comparable real-world data.
One of the Reddit users shared their practical experience related to synthetic data use cases: “The interesting part is that synthetic data works very differently depending on what you're training. For structured tasks (fraud detection, simulations, robotics, autonomous driving, edge cases, medical imaging augmentation), synthetic data can work surprisingly well because you can intentionally generate rare/high-value scenarios.”
For sensitive industries like finance and healthcare, sharing operational data for AI development is heavily restricted by compliance regulations. Nevertheless, synthetic tabular data generation via specialized architectures like TabDDPM allows teams to create statistically valid synthetic patient records or financial transactions. In such a way, they do not expose real individual identities and can easily pass privacy audits. TabDDPM handles mixed data types and combines categorical text and numerical figures into a structured spreadsheet.
Modern computer vision applications require hundreds of thousands of precisely annotated images to achieve high accuracy. Manual data collection and human labeling become a massive logistical bottleneck. Diffusion models streamline this entire process, as they convert simple text prompts into millions of labeled synthetic images. They auto-annotate themselves instantly during the generation process. For example, Tensorway utilizes custom diffusion model fine-tuning to generate domain-specific assets like logos. This gives companies access to massive visual datasets without the high costs of manual graphic production.
Real-world training sets are often highly focused on a dominant group. With synthetic data machine learning developers can generate precise examples of underrepresented classes to balance the dataset. This intentional data generation fixes systemic algorithmic bias and makes the final machine learning model much fairer under live user traffic. However, you should remember that if your initial seed data contains hidden biases, the diffusion model will actively amplify them. The well-known rule "garbage in, garbage out" applies to synthetic data as much as real data.
What Does Synthetic Data Generation with Diffusion Models Look Like in Practice?
To better demonstrate how to generate synthetic data, let’s take a healthcare AI team as an example. Engineers are building a diagnostic tool to spot rare brain anomalies. But they only have 800 labeled MRI scans at their disposal. This dataset is too small to train a reliable deep-learning model. However, waiting for new hospital collections is not an option. This could take months of ethical and bureaucratic approvals.
The engineers can fine-tune a pre-trained diffusion model directly on those 800 existing scans, instead of waiting. The system quickly learns the complex anatomical patterns and textures of the human brain to provide high-quality synthetic data for AI training. The team then uses the model to generate 4,200 entirely new synthetic MRI images. This rapidly expands their training pool to 5,000 diverse examples. And at the same time, they didn’t need to take any patient files or access external medical records.
The team validates the quality of generated images with strict engineering frameworks. This helps them make sure that these artificial scans are safe for production. For image generation, they track the Fréchet Inception Distance (FID) score. It mathematically proves how closely the synthetic data distribution matches the real-world samples.
For spreadsheets or financial tables, engineers can use the Train-on-Synthetic, Test-on-Real (TSTR) framework. It helps them verify that models trained on fake data can still predict real outcomes.
Wrapping Up
Waiting for real-world data collection or regulatory approval can stall a machine learning project for months. That’s why for highly specific medical and industrial applications, the use of synthetic data generation tools has become one of the most efficient ways to bypass such data bottlenecks. Diffusion models allow teams to generate rare edge cases and compliant datasets safely. And at the same time, engineers do not need to sacrifice statistical accuracy or user privacy.
To build these pipelines, you need to carefully optimize the balance between generation speed and data fidelity. Tensorway provides end-to-end generative AI development services to help your team design, tune, and safely validate custom data pipelines for your unique industry needs. Want to learn more? Contact us to discuss your project.


.jpg)


