
.jpg)
A multi-agent AI system is an architecture where several specialized AI agents handle different parts of a task and coordinate through an orchestrator or a peer-to-peer protocol.
In its own engineering blog about building the Research system, Anthropic reported a specific number. Multi-agent architectures consume roughly 15 times more tokens than a standard chat, which means they only make economic sense for tasks where the value of the output justifies that gain in performance. That's a notable admission from a company that actively promotes agentic AI rather than pushes back on it.
One practical takeaway follows from this. Multi agent AI is justified not where it's technically possible, but where the economics of the task can absorb the cost multiplier. Most articles about the topic show you how to assemble agents and skip the question of when you shouldn't bother in the first place. This piece comes at it from the other side, starting with the economics and the boundary conditions, and then moves on to the architecture, real-world use cases, and the reasons why most pilots never make it to production.
What Are Multi-Agent Systems in AI
At our AI agent development services, we design multi-agent systems — an architecture where a single task is carried out by several coordinated LLM agents instead of one. Each agent has its own role, its own system prompt, and its own set of tools it can access. They exchange intermediate results with each other through an explicitly designed coordination layer. That layer can be a separate orchestrator agent that decomposes the task and collects responses, or a message protocol that lets agents talk to each other directly. The standard working configuration in most production systems is an orchestrator plus several specialized workers. More complex setups add hierarchical levels, where a worker becomes an orchestrator for its own subordinate layer, or introduce dedicated validator agents that check outputs before they move further down the pipeline.
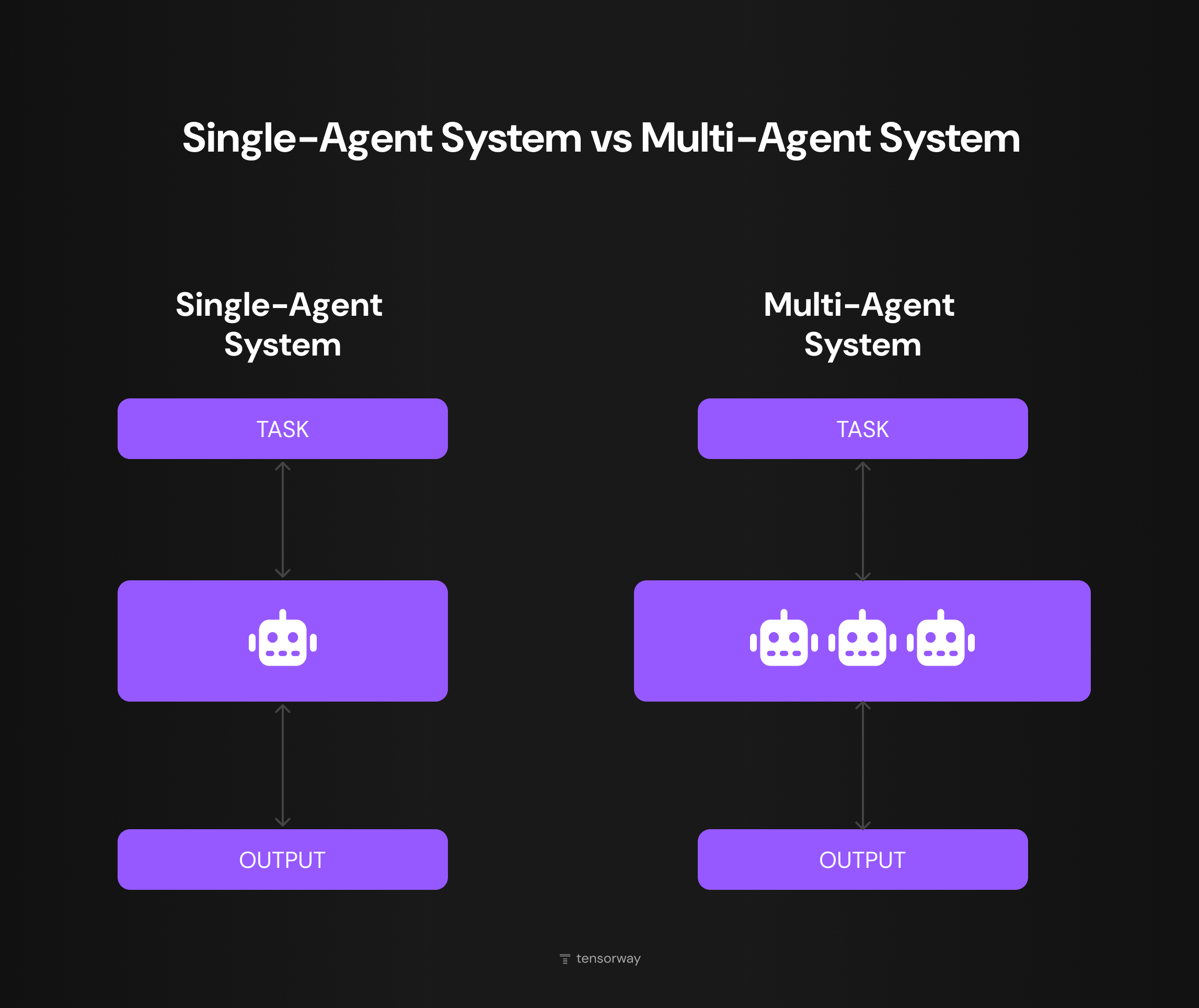
A single agent in this context is a program in which an LLM controls its own execution loop. It receives a task, sees the available tools, calls the one it needs, reads the output, and decides on the next step. The loop repeats until the task is closed or a limit kicks in. A single-agent system is one such loop with one system prompt. A multi agent system has several loops plus a coordination layer between them.
The shift from one agent to several started when engineering teams ran into the limits of a single loop. On tasks like legal review of long contracts, an agent runs out of context window long before it reaches a conclusion. On pipelines with a heterogeneous cost structure, such as cheap extraction followed by expensive reasoning, it ends up dragging everything through a single model. On top of that, there's the question of time. Independent subtasks that could naturally run in parallel are forced to run sequentially.
A multi-agent setup makes it possible to work around each of these limits, at the price of the coordination overhead that makes these systems more expensive to run. Multi agent vs single agent is a choice that shapes cost and reliability. This article shows where MAS earns its complexity, and where it doesn't.
What Are the Key Components of a Multi Agent System
A multi agent system as an engineering unit is built from five blocks. The set of decisions you make on each one determines whether the system stays cheap to maintain or turns into technical debt half a year after release.
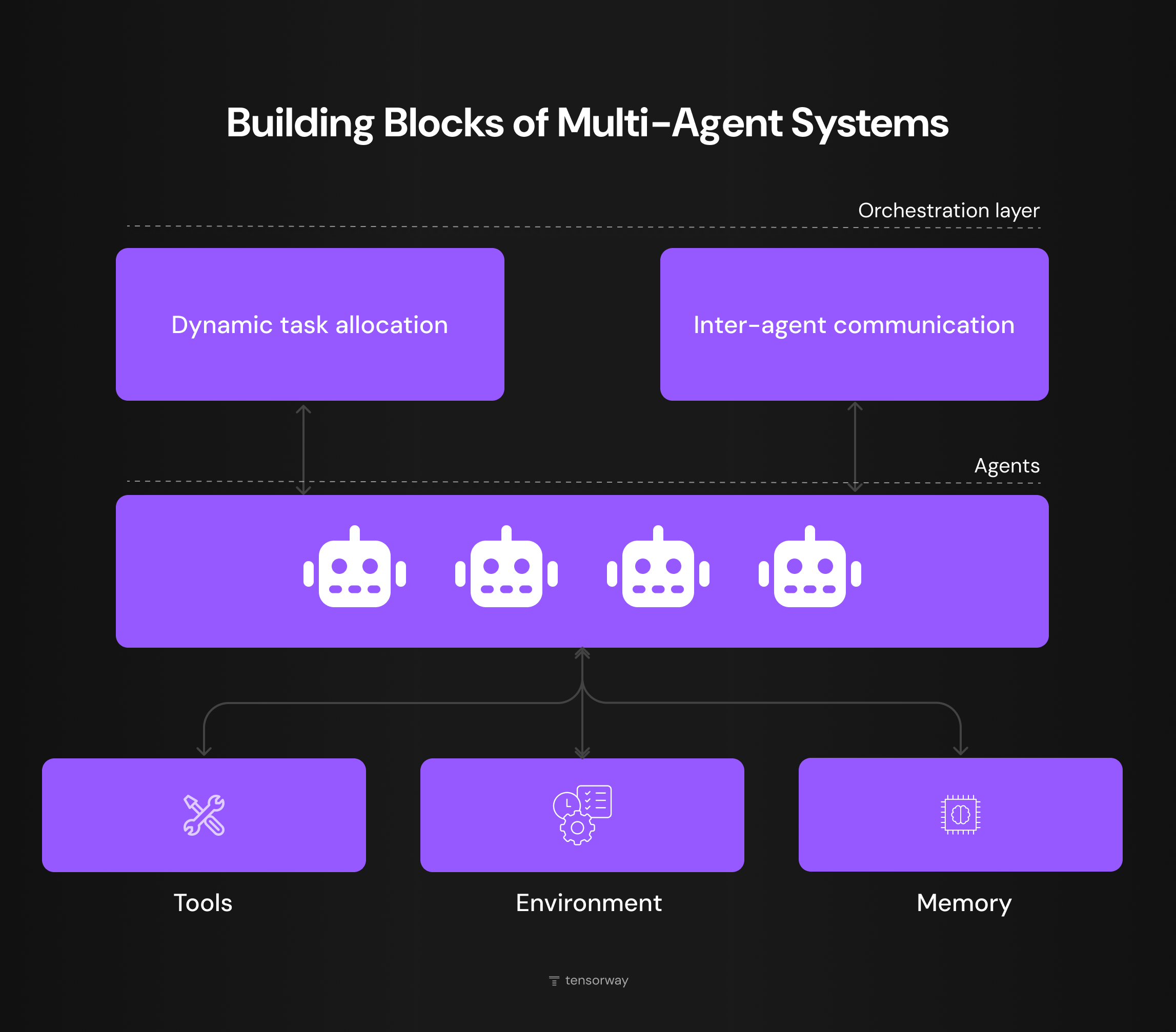
Orchestration Layer
The top layer responsible for dynamic task allocation and inter-agent communication, meaning who takes the next step and how agents pass results to each other. In production, this is either a dedicated LLM agent with stronger reasoning capability or a router model that follows routing rules. The choice depends on how dynamic the task is. Repetitive workflows can get by on rules, but open-ended research needs an LLM orchestrator.
Agents
The core of the system. Each agent is an LLM with its own system prompt, its own set of tools, and a limited scope of responsibility. The key engineering decision at this level is which model to use for which role. Production-grade multi-agent systems often combine several models, using cheaper ones for routine calls and more expensive ones for reasoning.
Picking and tuning these models is closer to machine learning engineering than to prompt design and wrong choice here costs more than any orchestration mistake later.
Tools
The external interfaces through which agents interact with the world outside their own tokens, such as APIs, databases, web search, and file I/O. The standard most modern integrations are built on is MCP, the Model Context Protocol from Anthropic. The quality of engineering at the tool level often decides whether a MAS makes it into production. Poorly designed tool descriptions break reasoning more often than imperfect prompts do.
Environment
The external setting the system runs in, whether that's a production application, a business process, or a user interface. For an engineer, this comes down to integration. How does the MAS receive a trigger to start, where does it send the result, and how are errors handled.
Memory
Without shared memory, agents lose track of each other's context after every reset, and the coordination loop has to start from scratch. In practice, this is handled by several storage layers, from vector databases for semantic search to key-value stores for intermediate state.
What Are the Main Architectural Patterns of Multi Agent Systems
The key components section answered the question of what a system is built from. Architectural patterns are about how those components are wired together. The standard classification used in multi agent systems documentation from LangGraph lists six configurations, which group into two families. Centralized and decentralized.
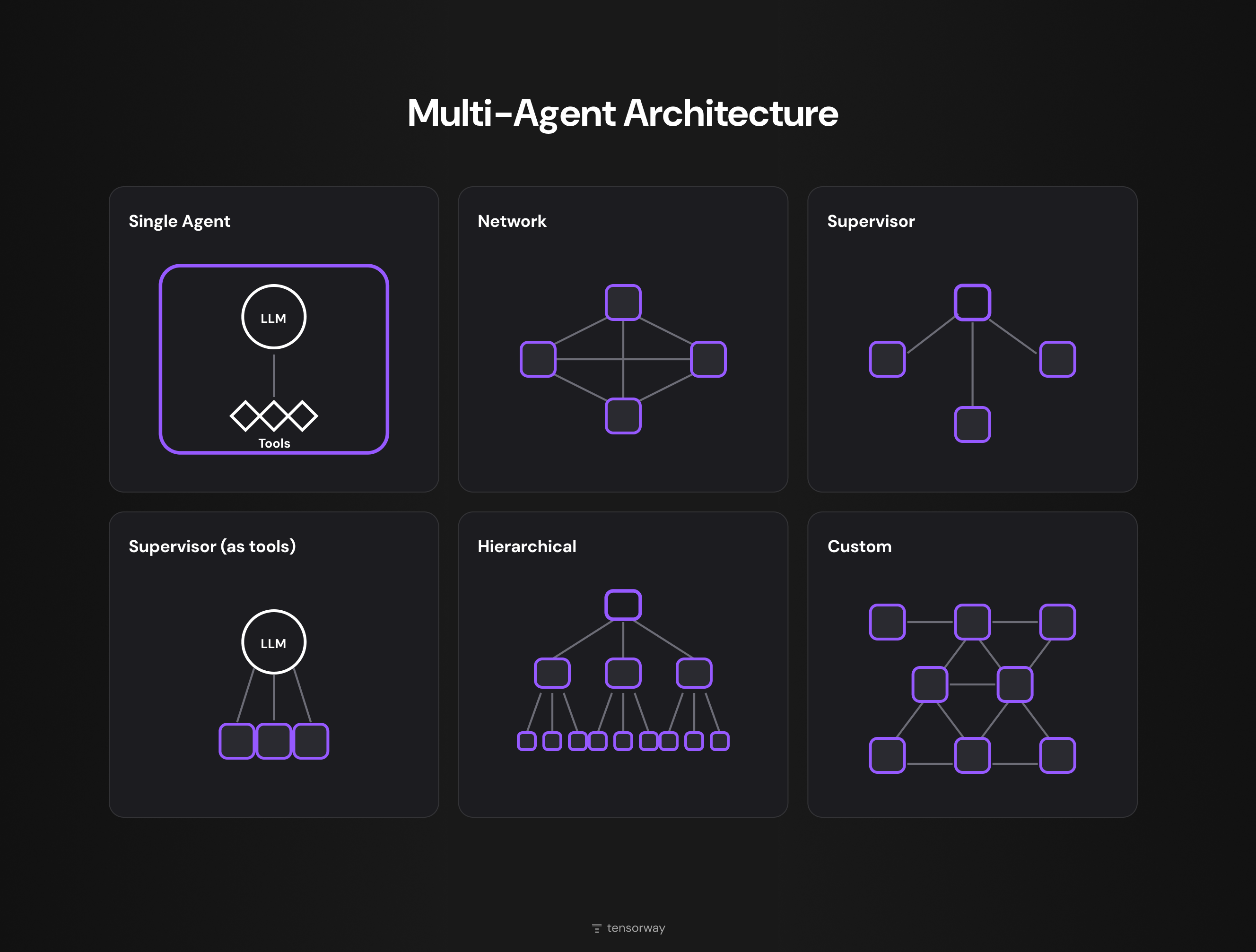
Centralized Patterns
- Supervisor. The most common production pattern. A single coordinator agent receives the task, hands subtasks out to workers, and aggregates their responses. Anthropic Research is built exactly this way. The Lead Researcher coordinates subagents that work in parallel on different aspects of the query. The advantage is a predictable flow that's easy to monitor and debug.
- Hierarchical. Supervisors over supervisors over workers. This makes sense when the task is too broad for one coordinator to hold. Enterprise systems with dozens of domains, each with its own logic, are a typical example.
- Supervisor (as tools). A special case where the supervisor calls other agents through tool calling. Formally, this is a single-agent system with multi-agent behavior. It's worth knowing, because teams sometimes build a full-blown MAS where supervisor-as-tools would have been enough, and pay for that decision in tokens.
Decentralized Patterns
- Network. A full peer-to-peer mesh where any agent can reach any other agent. It's resilient against a single point of failure, but debugging it is close to impossible. Any call can trigger a cascade of unpredictable coordination loops. In practice, this works for simulation, multi-agent reinforcement learning, and distributed research tasks.
- Custom. Hybrid graphs that don't fit into the standard shapes. They usually appear as the evolution of centralized systems that have grown past their original scope. More often than not, this is an antipattern. The team couldn't keep complexity in check and patched around it instead of redesigning the system as hierarchical.
Multi Agent AI Use Cases
Multi agent AI in B2B contexts pays off where the task genuinely runs into one of the three limits from the previous sections. Below are six use cases where this kind of setup delivered a measurable business outcome.
Private Equity Deal Sourcing
One of our clients is a European PE fund headquartered in Stockholm, managing multi-billion euro portfolios across healthcare, fintech, and industrial services. Deal sourcing was eating up to 60 hours a week per analyst, and putting together a single valuation analysis took anywhere from two days to four weeks. A single-agent setup couldn't handle this, because the data for one deal is scattered across internal CRMs, financial databases, web scraping, and documents in all sorts of formats. This is a multi agent system example that pays off because one accepted investment decision covers the annual cost of the entire setup with room to spare.
We built the architecture as a supervisor with five sub-agents. The lead agent routes requests coming in from the chat interface. The Research Agent identifies investment targets through unstructured web content. The Evaluation Agent runs candidates through the client's proprietary methodology. The Financial Extraction Agent works through reports and regulatory filings. The Presentation Agent turns the analysis into a ready-to-go deck for the investment committee.
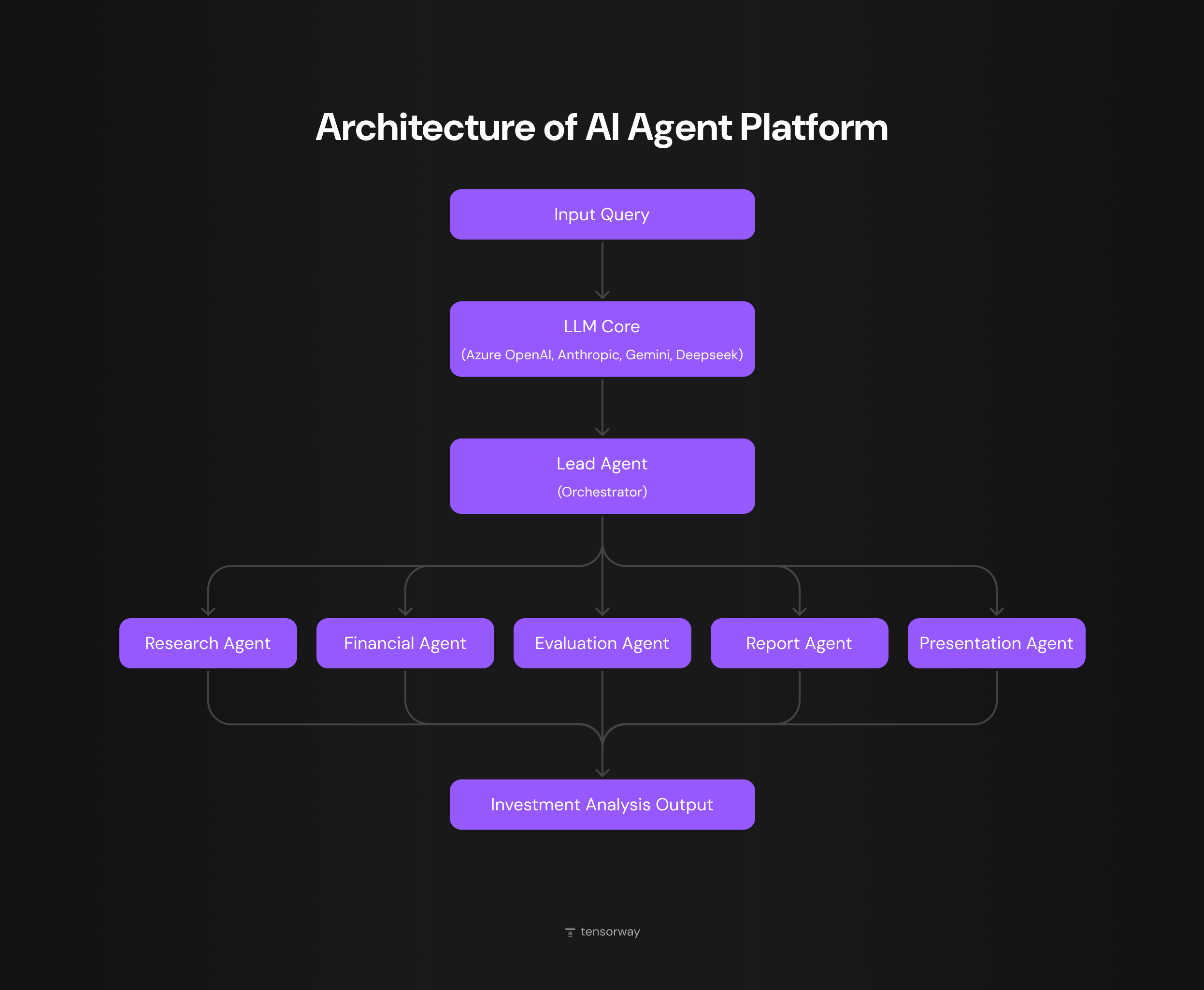
Today, 5 000 company profiles get processed in hours. Initial screening is five times faster, and an investment deck is now produced eight times faster than under the previous manual process.
Legal Document Processing for Benefits Cases
Another client is a US disability law firm helping clients secure SSDI, SSI, and Long-Term Disability benefits. A single case can run from a few hundred to ten thousand pages of medical records, including handwritten notes, scanned X-rays, lab results, and administrative paperwork. Processing one client manually used to take over a week.
This is another multi agent system example in a regulated environment, where the cost of the system is offset by the firm's ability to take on more cases without expanding headcount.
We built the system on LangGraph as a multi-stage pipeline. One agent filters out irrelevant pages. Text content goes through language models, while handwritten notes and scans are handled by a separate vision agent. A final agent assembles the summary, with every fact tied back to a specific page in the original document.
What used to take a week now gets processed in 5 to 15 minutes. The attorney works with a 60-page summary instead of thousands of pages of raw PDF.
Customer Service Routing in Regulated Industries
In industries like fintech or insurance, multi agent systems are deployed because every type of request comes with its own compliance rules, and those rules don't fit into a single system prompt. The standard solution is a supervisor with a tier-1 triage agent that classifies the incoming request, plus a set of specialized agents by category, with an optional human fallback for edge cases.
Multi-agent makes sense here for more than just speed. Each agent has a narrow scope, which makes compliance review much easier. The auditor can see exactly which specialized agent handled the request and which rules it followed.
Manufacturing Operations Orchestration
Manufacturing operations break down into functions that pull from different source systems. Demand forecasting reads from the ERP. Production planning reads from the MES. Predictive maintenance pulls IoT telemetry. A single agent trying to hold all of that in one context window hits its limits even at moderate scale.
In real-world deployments, these projects are built around a supervisor with specialized agents, each reading its own data stream. The specialized agents run in parallel and don't compete for tokens inside a shared context.
Clinical Decision Support in Healthcare
Medical workflows combine structured data, semi-structured EHR records, and unstructured physician notes. On top of that comes the regulatory layer, HIPAA in the U.S. and GDPR in Europe. A one-prompt agent over this kind of data either hallucinates or fails the compliance audit.
A multi-agent solution typically breaks down into a normalizer agent for data coming from different EHRs, a validator agent that checks the request against clinical guidelines, and a recommendation agent that always cites its source. The physician sees not just the system's conclusion but the chain of reasoning that led to it.
Software Engineering Agents
Code development is one of the few areas where multi-agent systems have made it broadly into public production. Claude Code, Cursor agents, GitHub Copilot are all variations on the same pattern, with a lead agent that decomposes the task and sub-agents for planning, code generation, testing, and review.
In its own engineering blog, Anthropic states plainly that coding is a worse fit for multi-agent decomposition than deep research or deal sourcing, because many subtasks are interdependent and don't parallelize cleanly. In practice, for most coding projects, a supervisor with a few sub-agents and a tight feedback loop works better than a full-fledged agent network.
How to Get Started with Multi-Agent AI Systems
Most teams working with multi agent AI get there through one of three paths. Each comes with its own cost curve and its own typical pitfalls. Knowing where your team stands today matters more than picking a framework or a model.
Path 1. PoC on a Specific Business Task
The team identifies a narrow bottleneck, such as preparing investment decks, processing medical records, or auditing vendors, and builds a multi-agent PoC to measure ROI on a single use case. The task is clearly defined, and the result is easy to compare against the manual process.
The problem with this path isn't the PoC itself but what happens after it. The PoC shows numbers on demo data and stays stuck there. The team didn't put in place an evaluation pipeline or assign ownership from day one, so there's nothing to carry the system from demo into production.
This is exactly what end-to-end AI development for B2B is meant to address – moving a working idea past PoC into a maintainable production system.
Path 2. Rewriting an Existing Single-Agent Setup
The team already has a working single-agent system that's hitting a ceiling. The context window can't hold the data volume anymore, latency is climbing, and accuracy is dropping on new edge cases. The logical next step is decomposition. The upside is that there's already a baseline to compare against.
The engineering dynamics here are different. Teams tend to decompose more aggressively than the task actually requires and end up with a system that's more complex than it needed to be. A useful rule from our own experience is to decompose only the step that genuinely doesn't fit a single-agent setup. If you can articulate why a single agent can't handle a specific step, that step is a candidate for its own agent. If you can't articulate it cleanly, the single-agent setup is probably still holding.
Path 3. Upgrading Legacy Automation
The team has an old rule-based or RPA stack and wants to replace it with something that handles unstructured data better. Multi-agent is attractive here because it lets you swap out dozens of rules for a reasoning agent while keeping the existing pipeline structure.
The biggest risk on this path is underestimating integration cost. The existing systems have their own APIs, their own data formats, and their own compliance constraints. The integration layer in a project like this often takes more resources than the agents themselves. Teams that only budget for the AI part run out of money before launch.
Final Thoughts
Multi-agent AI systems pay off where a single-agent setup can't hold the data volume, where different subtasks call for different models, or where the work genuinely benefits from running in parallel. In every other case, coordination overhead eats the gains faster than you can measure them. Tensorway has been building production AI since 2019, including multi-agent systems for private equity, legal, and fintech. If you're trying to figure out whether multi-agent is the right fit for your case, let's talk.




