
.jpg)
AI model drift is the gradual loss of accuracy in an ML model running in production, caused by the gap between real-world data and the data the model was trained on. The patterns the model learned during training stop describing reality over time, and its predictions become less and less reliable.
A study published in Nature tested 128 combinations of ML models and real-world datasets across healthcare, finance, transportation, and weather analytics. In 91% of cases, the models lost accuracy after deployment — a phenomenon known in the industry as AI model drift. The infrastructure was running fine, the code stayed the same, but the world the model ended up in eventually drifted away from the world it had been trained on.
That's what model drift is. It rarely shows up as an incident. More often, it's a slow slide in the metrics that the business notices as a drop in conversion rate or a spike in false positives a quarter after it actually started. Below, we break down how data drift differs from concept drift, how to catch drift before the customer does, and what to do once it's already happening.
What Is Model Drift?
Model drift is the gradual loss of predictive accuracy in an ML model caused by production data diverging from the data it was trained on. The model's weights, architecture, and inference code stay exactly the same. What changes is the environment the model operates in, and its predictions slowly start moving away from the truth.
That gap between training and production is the main reason an AI initiative can show strong results in the pilot and disappoint once it goes live. Machine learning model drift it's a continuous process that begins the moment a model starts serving real traffic. A PoC gets evaluated on a static dataset, with a train/test split, cross-validation, and fixed metrics. The team hits a result that meets the target and ships. Then the data starts to live its own life. Users change their behavior, the market shifts, upstream services update their schemas. The effect is amplified in deep learning systems, where the model's internal representations make drift harder to interpret than in classical ML. Without dedicated monitoring, this process stays invisible until a business metric drops far enough to show up on a dashboard in finance.
Example: Zillow Offers
This example doesn't illustrate ML drift in its purest academic form so much as the scale of the business fallout when a forecasting model gets out of sync with the market. Zillow Offers' algorithms combined statistical methods with elements of ML, which makes this a borderline case in strict academic terms. But the numbers and public disclosures make it the clearest illustration of what ignored drift actually costs.
Zillow Offers was the Zillow Group division that bought and resold homes based on prices generated by Zestimate. In the third quarter of 2021, the company wrote down $304 million in inventory because it had been buying homes at prices higher than its current estimates of future resale value. Over that same quarter, Zillow purchased 9,680 homes and sold 3,032. The company forecast another $240 to $265 million in losses for Q4, announced the full shutdown of Zillow Offers, and laid off roughly 25% of its workforce. CEO Rich Barton wrote to shareholders that the decision came down to unpredictability in home price forecasting that significantly exceeded what the company had expected. The model had been tuned for a market with stable price growth and couldn't adapt fast enough when post-pandemic conditions shifted.
Model Drift vs Data Drift vs Concept Drift
The model drift vs data drift distinction confuses even experienced ML teams. The term model drift exists as an umbrella name for ML model degradation in production. Underneath it sit two technically distinct phenomena with different underlying mechanisms, different detection methods, and different remediation paths. Without that distinction, teams pick monitoring tools at random and end up missing the exact type of drift that actually breaks the business metrics.
The distinction comes from the basics of statistical learning. An ML model approximates the joint distribution P(X, Y), the probability of seeing input data X alongside the target variable Y. This joint distribution decomposes into two components: P(X), the distribution of the inputs themselves, and P(Y|X), the conditional probability of the output given a particular input, which is the rule the model is actually learning to reproduce. Each of these components can shift independently of the other. That's where the two categories of drift come from, and each one calls for its own approach.
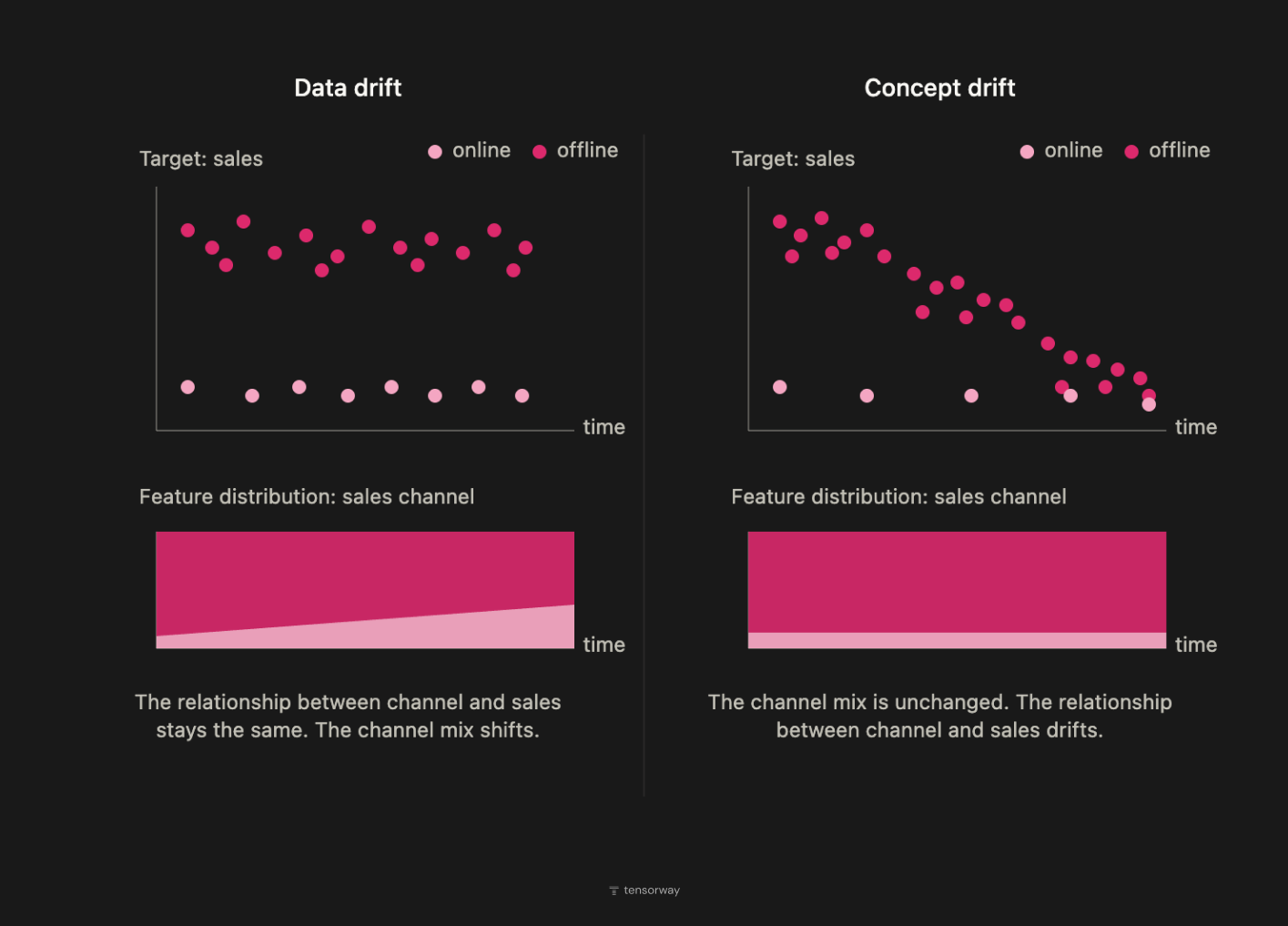
Data Drift
Data drift in machine learning is a change in the distribution of input data P(X) while P(Y|X) stays stable. The world keeps operating by the same rules, but the model starts running into input combinations that were underrepresented in the training set. It's the most common type of drift in systems that scale, whether through a new region, a new demographic, or an upstream service updating the data it generates.
Data drift lends itself well to automated monitoring. Statistical tests on the distribution, like Kolmogorov–Smirnov for continuous variables, Chi-squared for categorical ones, or the Population Stability Index as an aggregate metric, give a signal before the degradation reaches the business metrics. Fixing it usually comes down to retraining the model on the updated dataset or reweighting segments that had been underrepresented.
Concept Drift
Concept drift is a change in the rule P(Y|X) itself. The same inputs now map to a different correct output. This is a more fundamental shift. The model isn't just seeing different data, it's operating in a world where the very dependency it approximates has changed. Concept drift most often appears in places where system behavior depends on human or market decisions, like fraud detection, credit scoring, pricing models, and recommender systems under competitive pressure.
Detecting concept drift is fundamentally harder. The input distribution P(X) can stay identical, and every statistical test for data drift will show green. The only thing that drops is prediction quality, and the only way to catch it is to monitor performance metrics against real ground truth, which often arrives with a delay of days, weeks, or months depending on the domain. The fix isn't just fresh data. It calls for a review of features, problem framing, and sometimes the model architecture itself. In most cases, this means a separate ML cycle, not automated retraining.
Why AI Model Drift Happens
Drift isn't a sign of bad ML engineering. It's a structural property of any system that learns from data captured at one point in time and then runs on data that keeps coming in afterward. The world the model was trained in never matches the world it operates in. Understanding drift takes two angles, where it comes from and how fast it unfolds.
Where Drift Comes From
External change is the most common source. User behavior shifts, market conditions move, regulation gets updated, and the patterns the model learned stop being relevant. Demand forecasting models trained on pre-COVID data became the textbook example. Many of them broke within weeks once consumer behavior changed in March 2020. This category covers changes that happen outside the company's data infrastructure. It's a property of the world, not the system.
Internal pipeline changes are the least noticed cause. Someone in data engineering renames a column, switches units of measurement, updates an upstream schema, or modifies the feature engineering. The model receives an input that's formally valid but semantically different. Teams hunt for drift on the outside while it's actually originating inside their own data flow. In production systems with many data sources and regular pipeline updates, this is often the dominant cause.
Adversarial adaptation shows up wherever a model affects someone's incentives. Fraudsters learn to bypass detection rules, content creators learn to optimize for ranking algorithms, competitors adjust their prices to match the demand the model is predicting. This category drifts faster than the others because there's an agent on the other side actively working against the model.
How Fast Drift Unfolds
Drift is also classified by how fast it spreads. The taxonomy is well established in academic literature (Krawczyk & Cano, 2018; Webb et al., 2016) and it has operational consequences. The type of drift dictates the size of the monitoring window and the frequency of retraining cycles.
A monitoring system tuned for sudden drift will completely miss gradual drift. One tuned for gradual drift will keep firing noise on recurring drift. The mismatch between the type of drift and the monitoring parameters is one of the main reasons monitoring exists but doesn't actually work.
How to Detect Model Drift
Effective model drift detection relies on several monitoring layers working together. Each layer covers a particular class of drift and comes with its own signal latency. Teams that rely on just one layer are guaranteed to miss another type.
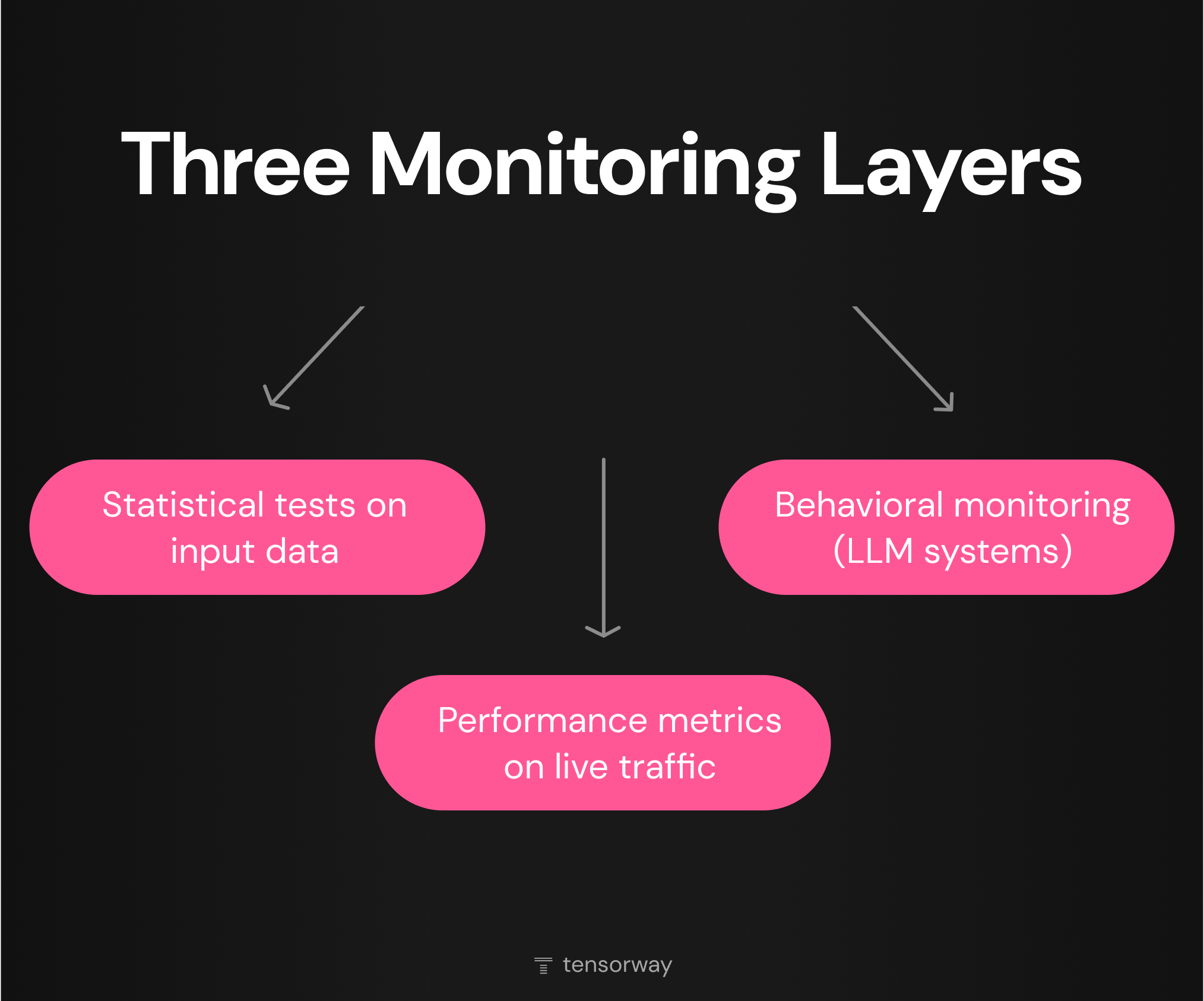
Statistical Tests on Input Data
Statistical tests compare the distribution of input features in production against the training distribution. The signal arrives quickly, usually well before the degradation reaches the business metrics. This is the cheapest monitoring layer in terms of compute, and it's the first one worth putting in place.
The toolkit depends on the feature type:
- Kolmogorov-Smirnov test for continuous variables. It compares the empirical distribution functions and returns a p-value on the shift.
- Chi-squared test for categorical variables. It works on discrete distributions and is sensitive to the appearance of new categories.
- Population Stability Index. An aggregate metric widely used in credit scoring and fintech. It produces a single number that's easy to use as a threshold metric on a dashboard.
- Kullback-Leibler / Jensen-Shannon divergence. For cases where you need to measure the distance between distributions without a binary drift / no drift output.
One important nuance. A statistical signal doesn't always point to a meaningful problem. A distribution can shift without affecting model accuracy, for instance when the shifting feature has low importance. The opposite also holds. A small change in an important feature might not pass the test threshold but already affect predictions.
Performance Metrics on Live Traffic
This is the only layer that reliably catches concept drift. As long as the team isn't measuring prediction quality against real ground truth, concept drift stays invisible. Statistical tests on input data show green while the model keeps making mistakes.
The baseline metric set depends on the task type:
- Classification: accuracy, precision, recall, F1, AUC.
- Regression: MAE, RMSE, MAPE.
- Ranking: NDCG, MRR, hit rate.
In domains with high ground truth latency, direct performance monitoring doesn't deliver a timely signal. By the time the drift becomes obvious, it's already costing money. A partial solution is proxy metrics:
- Prediction drift, the shift in the distribution of the model's own outputs. If the model suddenly starts producing more "high risk" classifications, that's a signal even without ground truth.
- Confidence drift, changes in the distribution of prediction confidence. A drop in confidence often precedes a drop in accuracy.
- Feature correlation drift, changes in the correlation structure between input features.
None of these replaces real performance monitoring, but together they form a useful early-warning channel.
Behavioral Monitoring for LLM Systems
Classical metrics don't transfer cleanly to generative outputs. Accuracy isn't defined on open text. Precision and recall don't apply where the "right answer" is a wide range of acceptable phrasings rather than a single label. LLM-based systems need their own monitoring layer.
The core metrics:
- Hallucination rate, the share of outputs containing factually incorrect statements. Usually measured through a separate evaluator model or human-in-the-loop sampling.
- Response quality scoring, output quality assessed against a rubric covering relevance, completeness, and tone. Can be done via LLM-as-a-judge or expert sampling.
- Policy violation rate, the share of outputs that breach defined constraints (toxic content, PII leakage, off-topic responses).
- Semantic similarity drift, the shift in the semantic distribution of outputs against a baseline. Useful for catching cases where the model starts to systematically "sound different."
In production systems with LLM agents, these become deployment gate metrics. A new model version or prompt doesn't ship to production until it passes the evaluator cycle on every key metric.
How to Prevent and Mitigate Drift
Build Monitoring into the Pipeline Up Front
Preventing AI model drift in production starts with treating monitoring, retraining, and rollback as one connected system rather than separate concerns. ML model monitoring is a required part of production deployment, on the same level as logging or alerting. Model drift monitoring, specifically, gives the team early warning that something in the world or the data pipeline has shifted. Without it, pipeline automation creates an illusion of control. The model retrains and ships on a regular cadence, but nobody actually knows whether that's a response to real drift. In the ML systems Tensorway takes to production, drift monitoring is built into the architecture from the start, not bolted on later under the pressure of an incident.
Define Retraining Triggers
Retraining on a calendar is the most common mistake in production ML, and a sign that ML model monitoring isn't connected to the retraining decision. A monthly cron doesn't react to sudden drift and burns resources during quiet periods. The setup that actually works combines three triggers. Schedule-based as a baseline (monthly or quarterly), drift-based when statistical thresholds are crossed, and performance-based when ground truth metrics start to slip. The schedule covers recurring drift, the drift-based trigger catches sudden and gradual shifts, and the performance-based one responds to concept drift in domains with fast feedback.
Validate the Data Before Retraining
Retraining on data that contains an undiagnosed pipeline bug bakes the problem into the model itself. Before kicking off a retraining run, make sure the degradation is actually drift and not a broken ETL, an upstream schema change, or a bug in feature engineering. Otherwise the team trains a new model on the same corrupted data and gets the same result.
Design the Architecture Around Rollback
A newly retrained model can perform worse than its predecessor, especially if the training data was partially contaminated or if drift was already in progress. In production ML, the ability to roll back a deployment quickly matters as much as the ability to retrain quickly. The baseline infrastructure for this is a model registry with versions and metadata, a canary deployment serving 5-10% of traffic before a full release, and automatic rollback on drift or quality metrics without human intervention. Tensorway's approach to AI development treats rollback as a first-class architectural concern, not an afterthought added once something breaks in production.
Treat Online Learning with Caution
Online learning, where the model updates on new data continuously, sounds like the ideal answer to drift but rarely turns out to be the optimal choice in practice. Catastrophic forgetting causes the model to lose older patterns as it learns new ones. In systems with feedback loops, online learning deepens the loop instead of weakening it. There's no clean previous version to roll back to, because the model is the product of its entire update history. For most business tasks, regular scheduled retraining with drift-triggered overrides is more reliable
Conclusion
AI model drift is normal behavior for any production model that runs longer than a few months. The question is how fast the team spots it and how much the response costs. The distinction between data drift and concept drift dictates the choice of model drift detection tools. Monitoring built into the architecture from the start catches drift earlier and costs less than monitoring added retroactively.
If your team is taking its first AI system into production or watching model accuracy slip, talk to the Tensorway team and we'll look at where your architecture is exposed to drift and what to do about it.

.jpg)