

Say "Hey Siri" – and your phone is already searching for an answer. Ask "Alexa, what's the weather?" – and you'll know the forecast in a second. What once looked like a scene from science fiction today simply turns on the music in your kitchen.
The AI market in voice assistants is growing at a staggering pace – from $3.54 billion in 2024 to $13.85 billion in 2029, with an average annual growth rate of over 31%.
%20In%20Voice%20Assistants%20Global%20Market%20Report%202025.png)
Behind this explosive trend lies audio analysis – the technology that allows machines to "hear" and understand sounds just like us. Thanks to deep learning development services, processing unstructured audio is transforming into a powerful tool for businesses across diverse industries.
Types of Audio Data
In this article, we'll explore what audio analysis is, why it has become the foundation of innovation, and how machine learning is changing the game in the world of sound.
Before discussing algorithms and models, it’s essential to clearly understand what they actually work with. In machine learning, "audio" isn’t just the sound we hear – it’s various ways of representing it as numbers. By choosing the format, we effectively determine what the model will "see" and how quickly (or slowly) it can find patterns.
- Raw audio waveforms. A digital representation of the sound signal in the time domain. It provides the most complete information about the audio signal, including its shape and nuances, but requires significant computational resources to process.
- Spectrograms. A visual representation of a signal’s frequency spectrum over time (X-axis: time, Y-axis: frequency, color: intensity). This is an effective way to transform sound into an "image," which CNN models can easily process.
- MFCCs (Mel-Frequency Cepstral Coefficients). A numerical representation based on the Mel spectrum, using Discrete Cosine Transform (DCT). It approximates human sound perception and is a compact way to encode audio.
- Chroma features (Chromagram). Describe sound energy across 12 tonal classes (chroma), regardless of octave. Useful in music processing, chord recognition, and melody harmonicity analysis.
Why Break This Down Now?
Because the audio format is the starting point of any ML project in this field. Understanding what lies "under the hood" of audio data makes it easier to choose the right model architecture, optimize computations, and avoid errors when the algorithm "misses the point." It’s like choosing a language for communication. It determines how efficiently you and the machine will understand each other.
What Is Audio Analysis?
This term can be defined as the process of transforming, examining, and interpreting audio signals. All these actions are aimed at extracting meaningful information. This process includes the application of different techniques and methods. Their exact set depends on the specific goals of the performed sound analysis.
Solutions with such functionality are actively gaining popularity in different domains. Among them, we can name gaming, entertainment, education, manufacturing, healthcare, and others. And yet, advancements in this sphere are moving forward! This means that quite soon, we are likely to observe the introduction of new cutting-edge solutions that may find their use in absolutely new spheres.
Applications of Audio Analysis With Machine Learning
Talking about the analysis of sounds, it’s worth mentioning its various use cases and applications. Below, we explore key directions with explanations and real-world project examples.
Sound Event Detection
Identifying and classifying specific sounds within an audio stream. The algorithm listens to the environment and signals when it detects predefined events (gunshots, alarms, breaking glass, or falls). SED is widely used in security, industrial settings, and healthcare where rapid incident response is critical.
San Jose (USA) implemented an acoustic gunshot detection system analyzing real-time microphone data. Initial accuracy was ~50%, but after algorithm refinements, it reached 81%, significantly reducing false alarms and accelerating police response.
Speech Recognition
Converting spoken language into text, enabling systems to understand voice commands or transcribe conversations. Often combined with NLP for contextual analysis. Used in virtual assistants, transcription services, call centers, and medical dictation.
Google integrated Speech-to-Text in its contact center to auto-transcribe calls, extract keywords, and sync them with CRM. This cut processing time and reduced operator workload.
Speaker Identification
Analyzing vocal characteristics to verify a speaker’s identity. Each person’s unique "vocal fingerprint" allows algorithms to recognize individuals. Applied in secure authentication, personalized services, and forensics.
BioVox by DTec is an advanced text-independent voice verification system that can enroll a user from just a few seconds of free speech, even across different languages and communication channels like phone or online video. Once a “voiceprint” is created, the system can automatically identify the same user in future audio inputs.
Audio Classification
Assigning sound clips to categories (e.g., music genre, noise type, animal species). Used in music platforms, environmental monitoring, and smart cities.
Researchers developed a two-stage system based on convolutional neural networks to automatically detect gunshots in the tropical forests of Belize, achieving up to 80% detection accuracy. This approach helps efficiently monitor poaching and reduces the volume of audio data for manual review.
Music Information Retrieval
Extracting musical features like tempo, key, harmony, mood, and instrumentation. Powers recommendation systems, DJ software, and musicology research.
Spotify’s Discover Weekly is an auto-generated playlist tailored to each user by analyzing audio features like mood, danceability, and energy, offering tracks that match the emotional tone of their listening history rather than just the genre.
Emotion Detection
Analyzing intonation, timbre, and speech pace to determine emotional state. Enhances customer service, gaming, and interactive apps.
Cogito’s call center platform detects customer stress/frustration in real-time, guiding agents to adjust communication tone. This boosts satisfaction and reduces escalations.

AI Sound Recognition: Fundamentals of Audio Data
Implementing AI-powered audio recognition can be a very promising idea for your solutions. But to do it in the right way, you should have at least the most general understanding of sound data.
What is sound data? It can be explained as analog sounds in a digital form that keeps all the key properties of the original ones. There are three main characteristics that should be taken into account in the context of audio detection and analysis.
- Time period. It is probably the simplest characteristic to explain. It shows how long a particular sound lasts in seconds, minutes, or hours.
- Amplitude. This is the intensity of the sound. It corresponds to the loudness of the sound and is measured in decibels (dB).
- Frequency. This characteristic indicates the pitch of the sound and is measured in Hertz (Hz). It shows the number of sound vibrations per second. The hearing range of a human covers the frequencies from 20 Hz to 20 kHz. Low-frequencies are perceived as bass, high-frequency sounds are treble.
Audio is included in the category of unstructured data. However, it is possible to define its format and choose one of them for storing sounds.
- WAVE (WAV, Waveform Audio File Format). It’s a raw audio format that will allow you to store it without compressing it. The format was developed by IBM and Microsoft.
- AIFF (Audio Interchange File Format) by Apple. This format also helps keep files without compression.
- MP3 (mpeg-1 audio layer 3) by the Fraunhofer Society in Germany. This format is probably the most well-known one. It started gaining popularity together with the adoption of portable devices for listening to music. MP3 compresses files. Nevertheless, you still can enjoy rather high sound quality.
- FLAC (Free Lossless Audio Codec) by Xiph.Org Foundation. This format ensures compression but the quality is not lost.
All these formats have their pros and cons. Still, when it comes to audio deep learning and machine learning development services, often you can’t just take a file in one of the mentioned formats and feed it to the model. The chosen data should be transformed so that a machine can work with it.
Preprocessing Techniques for Audio
Before an audio signal is fed into a machine learning model, it goes through several preparation stages. The quality of this process directly impacts prediction accuracy, model robustness to noise, and processing speed. Below are the key steps.
Resampling and Trimming
Resampling adjusts the sampling rate of audio so that all data share a consistent format, reducing unnecessary conversions during training. Trimming removes silence or irrelevant segments at the beginning and end of the recording, keeping only the informative part.
Noise Reduction
Noise from microphones, the environment, or transmission channels can degrade input quality. Spectral subtraction algorithms or adaptive filtering help preserve essential audio characteristics while removing unwanted background noise.
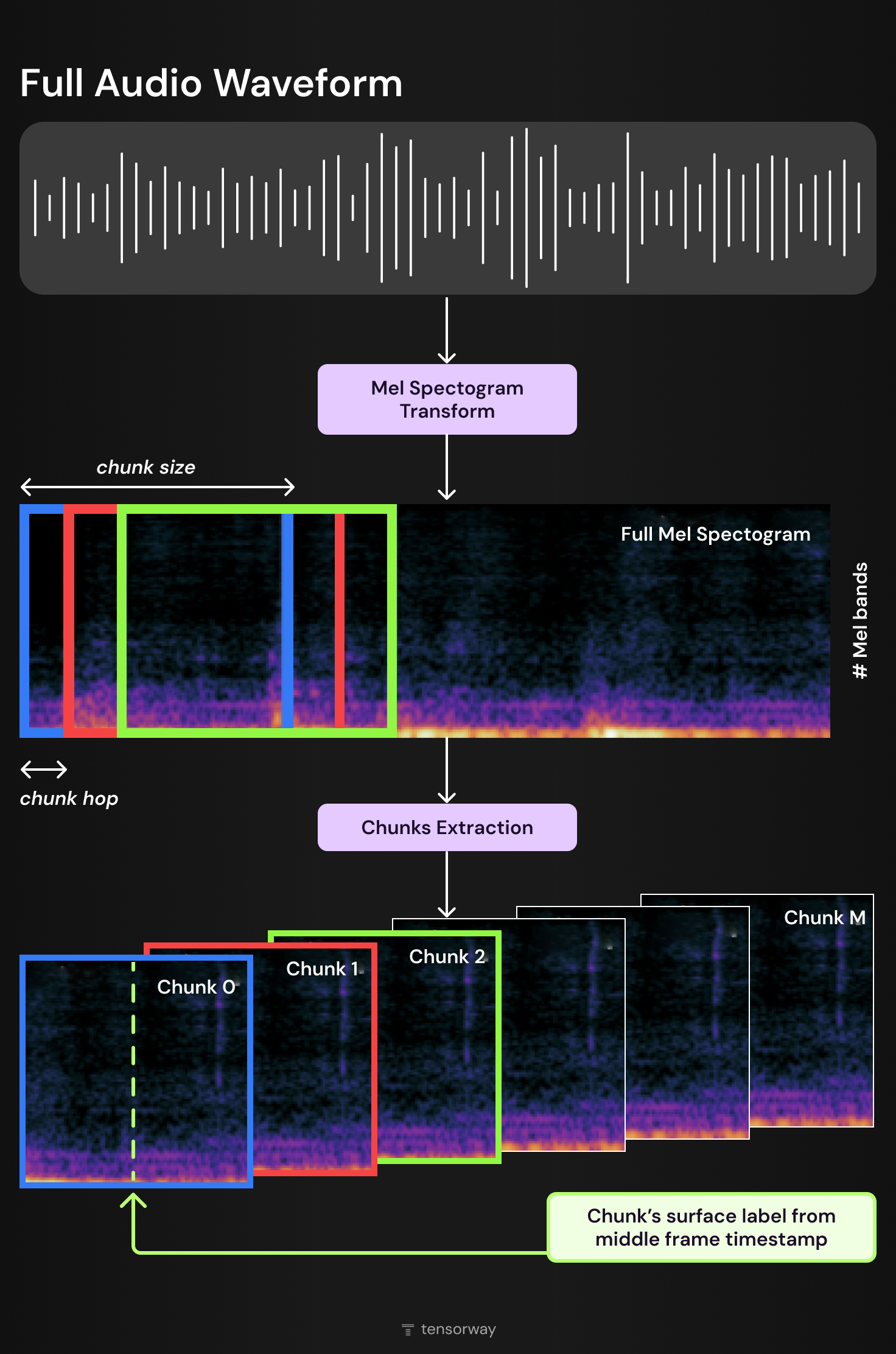
Segmentation and Mel-Spectrogram Transformation
Long audio recordings are divided into smaller parts (chunks) to simplify processing and present the model with a more manageable data format. Before segmentation, the signal is often transformed into a Mel spectrogram – a time-frequency visual representation of audio. This enables the use of computer vision approaches for audio processing.
The typical pipeline for this process is shown below:
- Raw audio waveform is converted into a Mel spectrogram.
- The spectrogram is split into fixed-length segments (chunk_size) with an offset (chunk_hop).
- Each segment receives a label based on the middle time frame.
Feature Extraction
At this stage, audio is converted into numerical feature vectors. Popular libraries – librosa (Python) and torchaudio (PyTorch) – allow you to extract:
- MFCC (Mel-frequency cepstral coefficients)
- Spectrograms and chroma features
- Tempograms and other parameters
Selecting the right features determines how well the model can separate useful signals from noise and detect patterns in the data.
Model Architectures for Audio ML
Different audio representations – raw waveforms, spectrograms, MFCCs – require different modeling approaches. Below are the key architectures, with practical code inserts that you can adapt to your own pipeline.
CNNs for spectrograms
Concept. When converting audio into a Mel spectrogram (time on the horizontal axis, frequency on the vertical axis, intensity as color), the problem becomes similar to image processing. CNNs excel at detecting local time-frequency patterns such as speech formants or distinctive transitions in music.
When to use. Sound and scene classification, music genre recognition, event detection in fixed time windows. The advantage is straightforward inference optimization, while the drawback is sensitivity to spectrogram generation parameters.
Code example. A basic CNN for Mel spectrogram classification in PyTorch, showing signal transformation and input preparation.
1import torch
2import torch.nn as nn
3import torchaudio
4
5# Load and prepare audio
6wav, sr = torchaudio.load("example.wav")
7wav = torch.mean(wav, dim=0, keepdim=True)
8
9mel = torchaudio.transforms.MelSpectrogram(
10 sample_rate=sr, n_fft=1024, hop_length=256, n_mels=128
11)(wav)
12mel_db = torchaudio.transforms.AmplitudeToDB()(mel)
13x = mel_db.unsqueeze(0)
14
15class AudioCNN(nn.Module):
16 def __init__(self, num_classes):
17 super().__init__()
18 self.backbone = nn.Sequential(
19 nn.Conv2d(1, 16, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
20 nn.Conv2d(16, 32, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
21 nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.AdaptiveMaxPool2d((8, 8))
22 )
23 self.head = nn.Linear(64 * 8 * 8, num_classes)
24
25 def forward(self, x):
26 z = self.backbone(x)
27 z = torch.flatten(z, 1)
28 return self.head(z)
29
30model = AudioCNN(num_classes=10)
31with torch.inference_mode():
32 preds = model(x)
33 probs = preds.softmax(dim=-1)
34print(probs)This snippet shows standard signal preprocessing for CNNs, correct tensor preparation, and adaptive pooling for handling variable-length inputs. You can scale this to architectures like ResNet or EfficientNet.
RNNs and LSTMs for sequential features
Concept. When the input is a sequence of features (MFCCs or frame-wise embeddings), recurrent networks such as LSTMs or GRUs capture temporal dependencies by retaining information about previous states.
When to use. Automatic speech recognition, emotional analysis of short utterances, melody or accompaniment generation. In modern projects, RNNs are often combined with CNNs or replaced by Transformers, but for resource-constrained environments, LSTMs remain highly effective.
Transformers and Self-Attention
Concept. Self-attention mechanisms can capture both local and global dependencies in audio simultaneously. This makes Transformers versatile for processing long speech or audio sequences.
When to use. End-to-end speech recognition models, self-supervised representation learning, and multimodal systems combining audio and video.
Pretrained models (YAMNet, OpenL3, wav2vec 2.0, Whisper)
Concept. Using pretrained models allows you to extract high-quality features or get classification results without training from scratch. This speeds up prototyping and improves results on small datasets.
Code example. Quick audio classification with YAMNet using Hugging Face.
1from datasets import load_dataset
2from transformers import pipeline
3
4clf = pipeline(task="audio-classification", model="harritaylor/yamnet")
5ds = load_dataset("ashraq/esc50", split="test")
6sample = ds[0]["audio"]
7
8preds = clf(sample["array"], sampling_rate=sample["sampling_rate"])
9
10for p in preds[:5]:
11 print(f"{p['label']}: {p['score']:.3f}")This is a fast way to test baseline performance in your domain. If the model underperforms, you can use it as a feature extractor and add your own classification layer.
Tools and Libraries for AI Audio Recognition and Analysis
There is a row of powerful tools and libraries available for use in AI analysis of audio data. They offer a wide range of functionalities, from basic audio processing and feature extraction to more advanced possibilities. Let us share a couple of examples with you.
- librosa. A Python library for audio and music analysis, widely used for preprocessing, feature extraction, and music information retrieval.
- torchaudio. An official PyTorch audio library for loading, transforming, and augmenting audio data, fully integrated with PyTorch models.
- pyAudioAnalysis. A Python package offering audio feature extraction, classification, segmentation, and visualization tools for quick experimentation.
- openSMILE. A feature extraction toolkit popular in speech and emotion recognition research.
- Essentia. A C++ library with Python bindings for audio analysis and music information retrieval, including classification and segmentation.
- Hugging Face. A platform with pretrained audio models (e.g., wav2vec2, Whisper, YAMNet) ready for speech recognition, classification, and more.
- TensorFlow/Keras. A deep learning framework for building, training, and deploying custom audio ML models.
- PyTorch. A widely used deep learning framework offering flexibility and GPU acceleration for audio-related neural networks.
- Kaggle Audio Datasets. A repository of public datasets for speech recognition, sound classification, and music analysis.
- UrbanSound8K. A dataset of labeled urban sound excerpts across 10 categories, often used in environmental sound recognition.
- Matplotlib. A Python library for creating visualizations such as waveforms and spectrograms for analysis and debugging.
- Sonic Visualiser. A desktop application for detailed visualization and annotation of audio files.

Evaluation Metrics for Audio Machine Learning Models
Measuring the performance of audio ML models is just as important as building them. Different tasks require different evaluation methods – a model that excels in speech recognition might not perform as well in environmental sound detection if we judge it by the wrong metric. Below is a quick guide to the most common metrics and where they apply.
Challenges in Sound Analysis
Performing audio analysis with ML can be a very promising idea for projects of different types. However, it’s vital to remember about possible pitfalls that you can face. The more you know about them, the better you can prepare to address them.
- Quality of records. Differences in microphone quality, recording environments, and equipment can lead to variations in audio quality. All this may negatively impact the reliability of the analysis.
- Background noise. Real-world audio often includes some background noise like sounds or wind. Sometimes it can obscure the primary sound signal and complicate the analysis.
- Lack of labeled data. High-quality, labeled datasets are very important for training ML models. Nevertheless, you may not have enough labeled data for specialized audio analysis tasks.
- Computational complexity. Complex ML models may consume a lot of computing and memory resources. As a result, it can be very challenging to ensure their real-time performance.
- Multi-modal integration. Some tasks, such as video analysis, may require integrating audio analysis with analysis of other formats (modalities), like video and text. This can become a real challenge as models need to learn from and correlate multiple data sources.
Recent Trends and Innovations
GPU-Powered Audio Processing
Modern audio plugins (such as Anukari, sonicLAB, GPU Audio) leverage parallel GPU processing to run complex physical sound models and real-time processing – even on older GPUs or mobile devices.
The New Approach to Audio Anomaly Detection
The world is adopting unified frameworks that combine spectral filtering, classical features (MFCCs), embeddings (OpenL3), traditional models (SVM, Random Forest), and deep learning architectures. This marks a breakthrough in anomaly detection accuracy, even in noisy environments or in real-time.
Self-Supervised Learning (SSL) for Audio
Audio models are learning to recognize signals without labeled datasets – SSL methods (such as Audio Spectrogram Transformer) significantly improve the quality of classification, speech recognition, emotion detection, keyword spotting, and even speaker identification.
AI Glasses for People with Hearing Impairments
Scottish researchers are developing smart glasses that read lip movements, send data to 5G servers, and deliver “clean” speech to the user even in noisy environments. The prototype is expected to become a reality next year.
AI Decoding of Animal Sounds
Projects like Project Ceti and Interspecies.io are working to decode animal communication – using deep learning, large audio datasets, and affordable recorders (AudioMoth). The goal is to understand how animals communicate with each other and uncover the meaning behind these exchanges.
AI-Powered Event Reality through Live Captioning and Translation
At NAB Show 2025, ENCO showcased AI innovations for broadcast: real-time speaker identification via voice “fingerprints,” live captions, translation into dozens of languages, and mobile translators.
Our Experience
In this project, Tensorway worked with a client developing a fitness game. The game uses a ball attached to an elastic strap to a headband. The player must hit the ball to prevent it from falling, and the mobile app counts the number of hits and runs competitions between users.
The client's previous solution counted hits using audio analysis, but it often made mistakes due to background noise – requiring manual result verification.
To solve this problem, the Tensorway team developed a comprehensive ML approach for audio analysis:
- We recorded numerous examples of hits under various conditions and created meticulous labeling so the model would "know" which sounds were hits and which were background noise.
- We converted each audio segment into a spectrogram – a visual representation of frequencies and their changes over time. This allowed us to leverage computer vision techniques for audio analysis.
- We trained a computer vision model to recognize ball hits using these spectrograms. This approach significantly improved noise robustness and recognition accuracy.
- The algorithms were simplified and optimized to work in real-time even on smartphones with limited resources.
- We created a multi-step training process – from data collection and cleaning to deploying the finished model in mobile apps for Android and iOS.
As a result, counting accuracy doubled compared to the client's previous audio solution, and the need for manual score verification was eliminated.
Final word
Audio analysis with machine learning can be as helpful as tricky, in case you have never had any relevant experience. That’s why it’s always better to have a professional team by your side. And at Tensorway, we are always ready to give you a helping hand.
With our expertise in working with AI and ML models, we will be able to cope with any task. Just tell us about your idea and we will find the right approach to its realization. Let’s bring the digital future closer together!




