

TL;DR
- AI credit scoring applies machine learning to alternative data (rent, utilities, telecom, bank cash flow) to score people that traditional bureau models cannot.
- Results are measurable. Adding utility and telecom data lifted 2.5 million US consumers by an average of 13 points (World Bank). A peer-reviewed MIS Quarterly study (December 2024) found a 50-million-customer bank raised approvals and cut defaults at the same time.
- Consumer tools like Experian Boost help but unevenly. The average lift is around 13 points, and not every lender uses the same score.
- The real risks are bias, explainability, and consent, not prediction accuracy. Build fair-lending review and consented, FCRA-compliant data from day one.
Alternative data credit scoring uses non-traditional signals, things like rent, utility, and telecom payments, to assess people whom conventional models cannot score. Pair that data with machine learning and you get AI credit scoring: a system that finds repayment patterns in messy, high-volume inputs that a fixed scorecard would miss entirely.
The reason this matters is simple. Traditional scores leave a large group of people unscoreable, not because they are risky, but because they are invisible to the model. This article explains what alternative data is, how AI uses it, what the measured results look like, and where the approach still carries risk. Where a figure is time-sensitive, it is dated so you can judge how current it still is.
Here is the difference at a glance before we go deeper.
What is alternative data in credit scoring?
Alternative data in credit scoring is any information about a borrower that sits outside traditional credit-bureau history: rent and utility payments, telecom bills, bank-account cash flow, and in some markets mobile-phone usage. As of 2025, the World Bank describes fully reported non-financial payment data as a powerful tool for financial inclusion, especially in emerging markets where it is often the only data available for scoring.
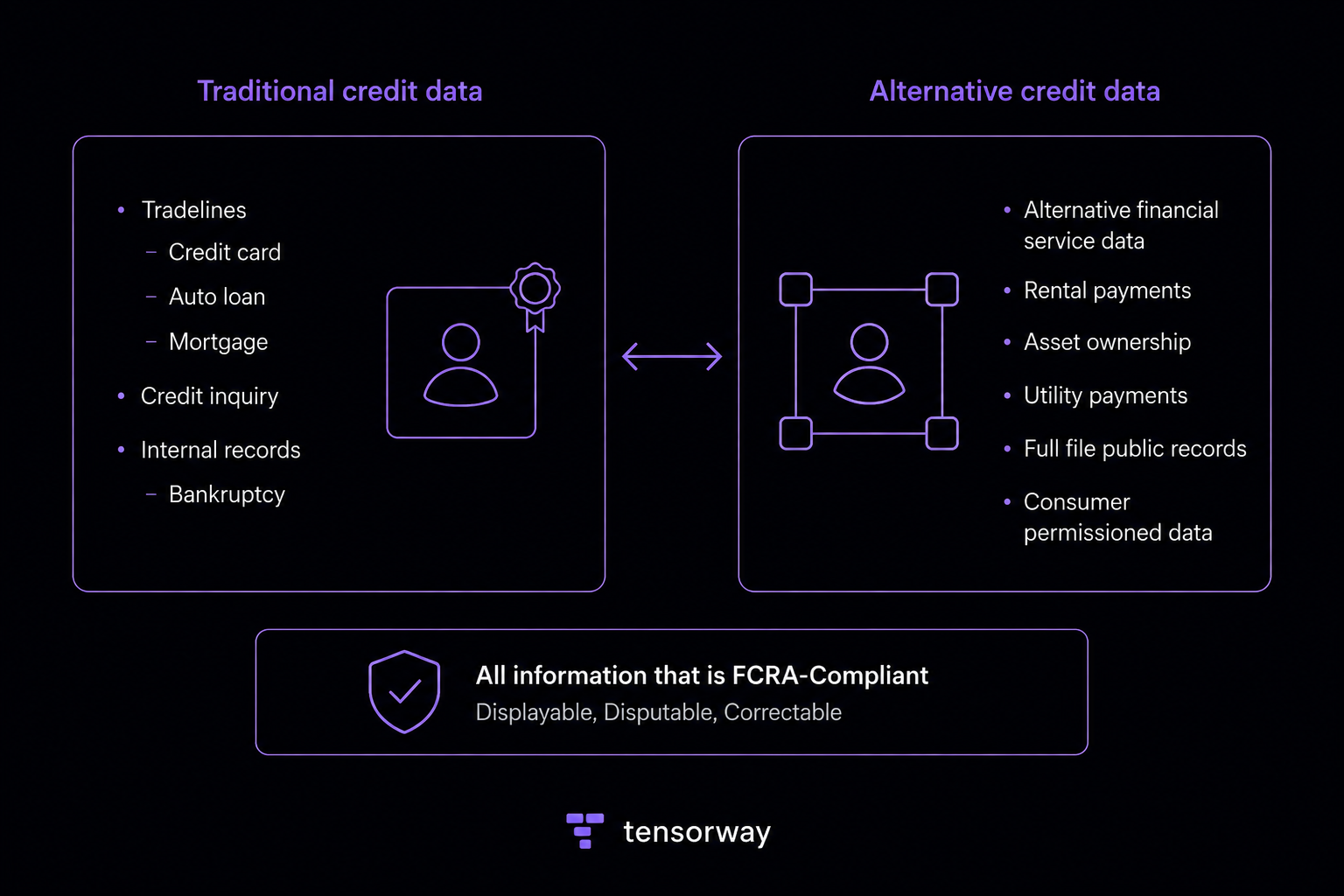
The contrast with traditional scoring is the key point. A FICO score is built mainly from credit-card usage, loan repayment, and debt levels, which gives a lagged view and excludes anyone without a borrowing record. Alternative credit scoring fills that gap by reading everyday financial behavior instead of only past borrowing.
Academic work supports the predictive value. A 2020 study in The World Bank Economic Review found that behavior revealed in mobile-phone usage predicts loan repayment, making it a viable substitute where formal credit history does not exist.
Why do traditional credit scores leave so many people out?
Traditional scores exclude millions because they require a borrowing history that many people simply do not have. The US Consumer Financial Protection Bureau coined the term credit invisible for this group, and its original 2015 analysis put the number at about 26 million Americans with no credit record, plus another 19 million with files too thin or stale to score.
The picture has improved but not closed. In a June 2025 update with corrected methodology, the CFPB found the credit-invisible share had fallen to 5.8% of adults, roughly 13.5 million people, by December 2020, with scored records rising from 81.6% to 87.5% of adults over the prior decade.
The gap also falls unevenly. CFPB analysis found about 15% of Black and Hispanic consumers were credit invisible compared with 9% of White consumers, a disparity that appears early in adult life and persists. This is the practical case for alternative credit scoring: a thin file is not the same as a risky borrower.
How does AI credit scoring use alternative data?
AI credit scoring applies machine learning to alternative data so the model learns repayment patterns rather than following a fixed rulebook. This is where machine learning credit scoring differs from a traditional scorecard: instead of a human assigning fixed weights to a handful of variables, the model derives weights from thousands of behavioral signals and updates as new data arrives.
In practice, automated credit scoring built this way handles three things a static model struggles with. It reads unstructured and high-volume inputs such as months of bank-transaction history. It captures behavioral credit scoring signals, like payment regularity, that a snapshot of debt levels misses. And it supports predictive credit scoring that can flag changes in risk in close to real time rather than on a lagged reporting cycle.
For teams building these systems, the engineering question is usually data pipelines and model governance, not the algorithm itself. Tensorway's machine learning services and a related customer segmentation model project give a sense of what that work involves in production.
What kinds of alternative data work best for credit risk modeling?
The most useful alternative data for credit risk is consented payment data: rent, utilities, telecom, and bank cash flow. These are predictive because they reflect recurring obligations, and they are defensible because, in the US, they fall under the Fair Credit Reporting Act when used in lending decisions.
Cash-flow data deserves a specific mention. As of 2025, Experian markets a Cashflow Score that uses consumer-permissioned bank-transaction data to score people who are thin-file or credit invisible but hold a bank account, with scores on the familiar 300 to 850 range (reported via Yahoo Finance). This matters for credit risk modeling machine learning work because cash flow shows capacity to repay directly, rather than inferring it from old borrowing. Tensorway's work on an AI financial agent for trading insights shows the kind of transaction-pattern modeling this depends on.
Which lenders already use AI credit scoring, and what did it change?
Several established lenders run alternative-data models in production today, and the independent evidence is starting to catch up with the vendor claims. The most credible data point is academic, not promotional: a peer-reviewed study in MIS Quarterly (December 2024) examined a bank serving more than 50 million customers that adopted AI credit scoring, and found the model increased approval rates and reduced default rates for underserved populations at the same time (reported analysis of the MIS Quarterly study, 2026). Better approvals and better risk separation together is the result that matters, because either one alone is easy to fake by moving the cutoff.
On the vendor side, the numbers point the same direction. Harvard research cited in a 2025 academic review reported that a Zest AI model used by more than 180 banks and credit unions increased loan approvals by 25% while holding risk constant, building on several hundred variables rather than the 10 to 20 in a traditional scorecard (IntechOpen, 2025). The same review noted that Upstart approves a substantially higher share of borrowers at the same loss rate compared with FICO-only models, and automates most approvals without a human in the loop.
The takeaway for a lender weighing this is not the exact percentage, which varies by portfolio and population. It is the shape of the result: when the model reads more signal and reads it well, the approval gain and the risk control move together rather than trading off.
What do real users say about alternative credit data tools?
Consumer experience is more mixed than the marketing averages suggest, which is worth knowing before you build on these tools. Tools like Experian Boost let people add rent, utility, and streaming payments to their file, and the reported average lift is about 13 points.
The nuance shows up in user reports. Some consumers describe their score dropping after using such a tool, though, as credit experts quoted by Bankrate explain, the tool only adds positive payments, so a drop usually traces to an unrelated factor such as closing a card and raising utilization. Two practical takeaways for anyone designing a scoring product: the lift is real but uneven, and not every lender consumes the same bureau or score, so a higher number does not guarantee a better decision everywhere. Setting that expectation honestly matters as much as the model.
What are the risks and limits of AI credit risk assessment?
The main risks in AI credit risk assessment are bias, opacity, and data quality, and none of them disappear just because the model is sophisticated. If the training data encodes historical discrimination, an AI credit risk assessment model can reproduce it at scale, which is why fair-lending review belongs in the build from the start, not as an audit afterward.
Three limits are worth stating plainly:
- Explainability. Lenders in most jurisdictions must give applicants a reason for denial. A model that cannot explain its decision is a regulatory problem, not just a technical one.
- Data privacy and consent. The defensible alternative data is consented and, in the US, FCRA-regulated. Scraping social or behavioral signals without consent invites both legal and reputational exposure.
- Digital and infrastructure gaps. The World Bank notes that realizing alternative data's promise depends on closing digital-literacy and infrastructure gaps, or the same people get excluded twice.
For fintech credit scoring teams, this is the real work: not proving a model can predict, but proving it predicts fairly, transparently, and on data you are allowed to use.
The short version
The strongest alternative credit scoring models in 2026 combine consented alternative data, rent, utilities, telecom, and bank cash flow, with machine learning that can read those signals and explain its output. The measured results are real: average score lifts in the low double digits, millions of previously unscoreable people brought into the system, and meaningful new lending volume.
The order of operations is what separates a useful system from a liability. Start with data you have clear consent to use, design for explainability and fair-lending review from day one, and validate the model on your own population before trusting its predictions. Done that way, fintech credit scoring with alternative data widens access without quietly importing the bias it was meant to fix.



